La regressió logística a la programació R és un algorisme de classificació utilitzat per trobar la probabilitat d'èxit i fracàs de l'esdeveniment. La regressió logística s'utilitza quan la variable dependent és de naturalesa binària (0/1, vertader/fals, sí/no). La funció logit s'utilitza com a funció d'enllaç en una distribució binomial.
La probabilitat d'una variable de resultat binària es pot predir mitjançant la tècnica de modelització estadística coneguda com a regressió logística. S'utilitza àmpliament en moltes indústries diferents, com ara màrqueting, finances, ciències socials i investigació mèdica.
La funció logística, comunament anomenada funció sigmoide, és la idea bàsica que sustenta la regressió logística. Aquesta funció sigmoide s'utilitza en la regressió logística per descriure la correlació entre les variables predictores i la probabilitat del resultat binari.

La regressió logística en la programació R
La regressió logística també es coneix com Regresió logística binomial . Es basa en la funció sigmoide on la sortida és probabilitat i l'entrada pot ser de -infinit a +infinit.
Teoria
La regressió logística també es coneix com a model lineal generalitzat. Com que s'utilitza com a tècnica de classificació per predir una resposta qualitativa, el valor de y oscil·la entre 0 i 1 i es pot representar amb la següent equació:
La regressió logística en la programació R
pàg és la probabilitat de la característica d'interès. L'odds ratio es defineix com la probabilitat d'èxit en comparació amb la probabilitat de fracàs. És una representació clau dels coeficients de regressió logística i pot prendre valors entre 0 i infinit. La proporció de probabilitats d'1 és quan la probabilitat d'èxit és igual a la probabilitat de fracàs. La proporció de probabilitats de 2 és quan la probabilitat d'èxit és el doble de la probabilitat de fracàs. La proporció de probabilitats de 0,5 és quan la probabilitat de fracàs és el doble de la probabilitat d'èxit.
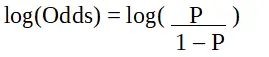
La regressió logística en la programació R
Com que estem treballant amb una distribució binomial (variable dependent), hem de triar una funció d'enllaç que s'adapti millor a aquesta distribució.
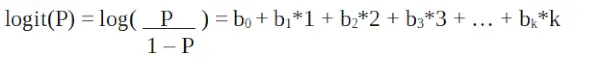
La regressió logística en la programació R
És un funció de logit . A l'equació anterior, el parèntesi s'escull per maximitzar la probabilitat d'observar els valors de la mostra en lloc de minimitzar la suma dels errors al quadrat (com la regressió ordinària). El logit també es coneix com un registre de probabilitats. La funció logit ha d'estar relacionada linealment amb les variables independents. Això és de l'equació A, on el costat esquerre és una combinació lineal de x. Això és similar a la suposició MCO que y està relacionada linealment amb x. Les variables b0, b1, b2... etc. són desconegudes i s'han d'estimar a partir de les dades d'entrenament disponibles. En un model de regressió logística, multiplicar b1 per una unitat canvia el logit per b0. Els canvis P a causa d'un canvi d'una unitat dependran del valor multiplicat. Si b1 és positiu, P augmentarà i si b1 és negatiu, P disminuirà.
El conjunt de dades
mtcars (prova de carretera de cotxes de tendència del motor) inclou el consum de combustible, el rendiment i 10 aspectes del disseny d'automòbils per a 32 automòbils. Ve preinstal·lat amb dplyr paquet en R.
R
quants zero per un milió
# Installing the package> install.packages>(>'dplyr'>)> # Loading package> library>(dplyr)> # Summary of dataset in package> summary>(mtcars)> |
>
>
Realització de regressió logística en un conjunt de dades
La regressió logística s'implementa en R utilitzant glm() entrenant el model utilitzant característiques o variables del conjunt de dades.
R
format de cadena en java
# Installing the package> # For Logistic regression> install.packages>(>'caTools'>)> # For ROC curve to evaluate model> install.packages>(>'ROCR'>)> > # Loading package> library>(caTools)> library>(ROCR)> |
>
>
Divisió de les dades
R
# Splitting dataset> split <->sample.split>(mtcars, SplitRatio = 0.8)> split> train_reg <->subset>(mtcars, split ==>'TRUE'>)> test_reg <->subset>(mtcars, split ==>'FALSE'>)> # Training model> logistic_model <->glm>(vs ~ wt + disp,> >data = train_reg,> >family =>'binomial'>)> logistic_model> # Summary> summary>(logistic_model)> |
>
>
Sortida:
Call: glm(formula = vs ~ wt + disp, family = 'binomial', data = train_reg) Deviance Residuals: Min 1Q Median 3Q Max -1.6552 -0.4051 0.4446 0.6180 1.9191 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercepció) 1,58781 2,60087 0,610 0,5415 pes 1,36958 1,60524 0,853 0,3936 disp -0,02969 0,01577 -1,882 0,01577 -1,882 0,0 --- Signif. codis: 0 '***' 0,001 '**' 0,01 '*' 0,05 '.' 0,1 ' ' 1 (El paràmetre de dispersió per a la família binomial es considera 1) Desviació nul·la: 34,617 en 24 graus de llibertat Desviació residual: 20,212 en 22 graus de llibertat AIC: 26.212 Nombre d'iteracions de puntuació Fisher: 6>
- Trucada: es mostra la trucada de funció utilitzada per ajustar el model de regressió logística, juntament amb informació sobre la família, la fórmula i les dades. Residus de desviació: són els residus de desviació, que mesuren el grau de bondat d'ajust del model. Representen discrepàncies entre les respostes reals i la probabilitat prevista pel model de regressió logística. Coeficients: aquests coeficients en regressió logística representen el log odds o logit de la variable de resposta. Els errors estàndard relacionats amb els coeficients estimats es mostren al Std. Columna d'error. Codis de significació: el nivell de significació de cada variable predictora s'indica mitjançant els codis de significació. Paràmetre de dispersió: en la regressió logística, el paràmetre de dispersió serveix com a paràmetre d'escala per a la distribució binomial. S'estableix en 1 en aquest cas, indicant que la dispersió suposada és 1. Desviació nul·la: la desviació nul·la calcula la desviació del model quan només es té en compte l'intercepció. Simbolitza la desviació que resultaria d'un model sense predictors. Desviació residual: la desviació residual calcula la desviació del model després d'haver ajustat els predictors. Representa la desviació residual després de tenir en compte els predictors. AIC: el criteri d'informació d'Akaike (AIC), que explica el nombre de predictors, és un indicador de la bondat d'ajust d'un model. Penalitza els models més complexos per tal d'evitar un sobreajustament. Els models que s'ajusten millor s'indiquen amb valors AIC més baixos. Nombre d'iteracions de puntuació de Fisher: el nombre d'iteracions que necessita el procediment de puntuació de Fisher per estimar els paràmetres del model s'indica pel nombre d'iteracions.
Prediu les dades de la prova en funció del model
R
predict_reg <->predict>(logistic_model,> >test_reg, type =>'response'>)> predict_reg> |
ordre lexicogràfic
>
>
Sortida:
Hornet Sportabout Merc 280C Merc 450SE Chrysler Imperial 0.01226166 0.78972164 0.26380531 0.01544309 AMC Javelin Camaro Z28 Ford Pantera L 0.06104267 0.02807992 0.01107943>
R
# Changing probabilities> predict_reg <->ifelse>(predict_reg>0.5, 1, 0)> # Evaluating model accuracy> # using confusion matrix> table>(test_reg$vs, predict_reg)> missing_classerr <->mean>(predict_reg != test_reg$vs)> print>(>paste>(>'Accuracy ='>, 1 - missing_classerr))> # ROC-AUC Curve> ROCPred <->prediction>(predict_reg, test_reg$vs)> ROCPer <->performance>(ROCPred, measure =>'tpr'>,> >x.measure =>'fpr'>)> auc <->performance>(ROCPred, measure =>'auc'>)> auc <- [email protected][[1]]> auc> # Plotting curve> plot>(ROCPer)> plot>(ROCPer, colorize =>TRUE>,> >print.cutoffs.at =>seq>(0.1, by = 0.1),> >main =>'ROC CURVE'>)> abline>(a = 0, b = 1)> auc <->round>(auc, 4)> legend>(.6, .4, auc, title =>'AUC'>, cex = 1)> |
>
>
Sortida:
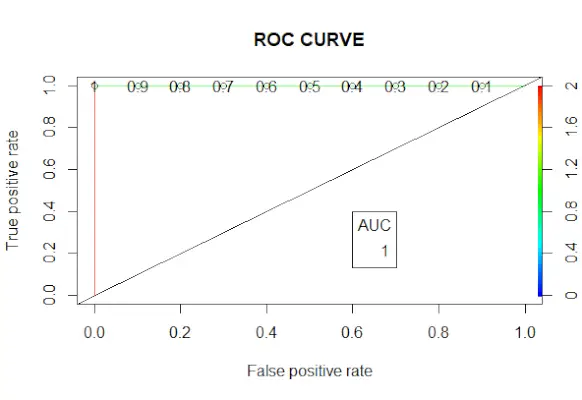
Corba ROC
Exemple 2:
Podem realitzar un model de regressió logística conjunt de dades del Titanic a R.
R
# Load the dataset> data>(Titanic)> # Convert the table to a data frame> data <->as.data.frame>(Titanic)> # Fit the logistic regression model> model <->glm>(Survived ~ Class + Sex + Age, family = binomial, data = data)> # View the summary of the model> summary>(model)> |
>
>
Sortida:
Call: glm(formula = Survived ~ Class + Sex + Age, family = binomial, data = data) Deviance Residuals: Min 1Q Median 3Q Max -1.177 -1.177 0.000 1.177 1.177 Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercepció) 4.022e-16 8.660e-01 0 1 Class2nd -9.762e-16 1.000e+00 0 1 Class3rd -4.699e-16 1.000e+00 0 1 ClassCrew -5.551.-001e 00 0 1 Sexe Femení -3.140e-16 7.071e-01 0 1 EdatAdult 5.103e-16 7.071e-01 0 1 (Paràmetre de dispersió per a la família binomial presa com a 1) Desviació nul·la: 44,361 graus de llibertat: 44.361 desviació 1 residual: en 26 graus de llibertat AIC: 56.361 Nombre d'iteracions de puntuació Fisher: 2>
Traceu la corba ROC per al conjunt de dades del Titanic
R
# Install and load the required packages> install.packages>(>'ROCR'>)> library>(ROCR)> # Fit the logistic regression model> model <->glm>(Survived ~ Class + Sex + Age, family = binomial, data = data)> # Make predictions on the dataset> predictions <->predict>(model, type =>'response'>)> # Create a prediction object for ROCR> prediction_objects <->prediction>(predictions, titanic_df$Survived)> # Create an ROC curve object> roc_object <->performance>(prediction_obj, measure =>'tpr'>, x.measure =>'fpr'>)> # Plot the ROC curve> plot>(roc_object, main =>'ROC Curve'>, col =>'blue'>, lwd = 2)> # Add labels and a legend to the plot> legend>(>'bottomright'>, legend => >paste>(>'AUC ='>,>round>(>performance>(prediction_objects, measure =>'auc'>)> >@y.values[[1]], 2)), col =>'blue'>, lwd = 2)> |
javafx a l'eclipsi
>
>
Sortida:
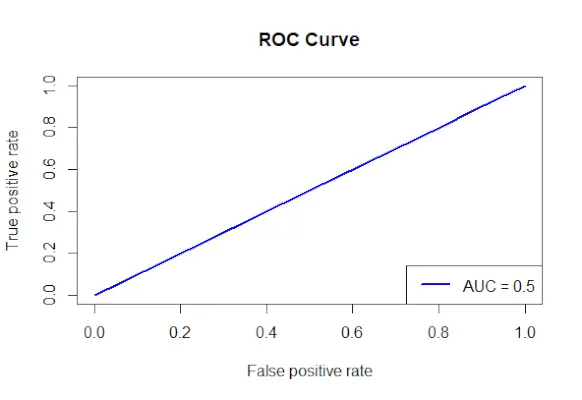
corba ROC
- S'especifiquen els factors utilitzats per predir Survived i s'utilitza la fórmula Survived Class + Sex + Age per crear un model de regressió logística.
- Mitjançant la funció predict(), es fan prediccions al conjunt de dades mitjançant el model ajustat.
- Les probabilitats projectades es combinen amb els valors reals del resultat per construir un objecte de predicció mitjançant el mètode prediction() del paquet ROCR.
- S'especifiquen la mesura de la taxa de positiu veritable (tpr) i la mesura de l'eix x de la taxa de fals positiu (fpr) i es crea un objecte corba ROC mitjançant la funció performance() del paquet ROCR.
- L'objecte corba ROC (roc_obj), que especifica el títol principal, el color i l'amplada de la línia, es representa mitjançant la funció plot().
- Utilitza la funció performance() amb mesura = auc per determinar el valor AUC (àrea sota la corba) i afegeix etiquetes i una llegenda a la trama.