A Xarxa neuronal convolucional (CNN) és un tipus d'arquitectura de xarxa neuronal d'aprenentatge profund que s'utilitza habitualment en visió per computador. La visió per ordinador és un camp de la intel·ligència artificial que permet a un ordinador entendre i interpretar la imatge o les dades visuals.
Quan es tracta d'aprenentatge automàtic, Xarxes neuronals artificials actuar molt bé. Les xarxes neuronals s'utilitzen en diversos conjunts de dades com imatges, àudio i text. Els diferents tipus de xarxes neuronals s'utilitzen amb diferents propòsits, per exemple per predir la seqüència de paraules que fem servir. Xarxes neuronals recurrents més precisament an LSTM , de la mateixa manera per a la classificació d'imatges fem servir xarxes neuronals de convolució. En aquest bloc, construirem un bloc bàsic per a CNN.
En una xarxa neuronal normal hi ha tres tipus de capes:
- Capes d'entrada: És la capa en què donem entrada al nostre model. El nombre de neurones d'aquesta capa és igual al nombre total de característiques de les nostres dades (nombre de píxels en el cas d'una imatge).
- Capa oculta: L'entrada de la capa d'entrada s'introdueix a la capa oculta. Hi pot haver moltes capes ocultes segons el nostre model i la mida de les dades. Cada capa oculta pot tenir diferents nombres de neurones que, generalment, són més grans que el nombre de característiques. La sortida de cada capa es calcula mitjançant la multiplicació matricial de la sortida de la capa anterior amb els pesos aprendre d'aquesta capa i després per l'addició de biaixos aprensibles seguit de la funció d'activació que fa que la xarxa no sigui lineal.
- Capa de sortida: La sortida de la capa oculta s'introdueix a una funció logística com sigmoide o softmax que converteix la sortida de cada classe en la puntuació de probabilitat de cada classe.
Les dades s'introdueixen al model i la sortida de cada capa s'obté del pas anterior s'anomena feedforward , llavors calculem l'error mitjançant una funció d'error, algunes de les funcions d'error habituals són l'entropia creuada, l'error de pèrdua quadrada, etc. La funció d'error mesura el rendiment de la xarxa. Després d'això, ens retropropaguem al model calculant les derivades. Aquest pas s'anomena La xarxa neuronal convolucional (CNN) és la versió estesa de xarxes neuronals artificials (ANN) que s'utilitza principalment per extreure la característica del conjunt de dades de matriu en forma de quadrícula. Per exemple, conjunts de dades visuals com imatges o vídeos on els patrons de dades tenen un paper important.
classificació de bombolles
Arquitectura CNN
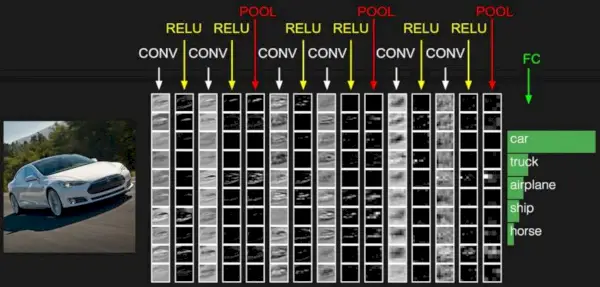
La xarxa neuronal convolucional consta de diverses capes com la capa d'entrada, la capa convolucional, la capa de agrupació i les capes totalment connectades.

Arquitectura CNN senzilla
La capa de convolució aplica filtres a la imatge d'entrada per extreure característiques, la capa de agrupació redueix la mostra de la imatge per reduir el càlcul i la capa completament connectada fa la predicció final. La xarxa aprèn els filtres òptims mitjançant la retropropagació i el descens del gradient.
Com funcionen les capes convolucionals
Les xarxes neuronals de convolució o covnets són xarxes neuronals que comparteixen els seus paràmetres. Imagina que tens una imatge. Es pot representar com un cuboide amb la seva longitud, amplada (dimensió de la imatge) i alçada (és a dir, el canal com a imatges generalment té canals vermells, verds i blaus).
Ara imagineu-vos agafant un petit pegat d'aquesta imatge i executant una petita xarxa neuronal, anomenada filtre o nucli, amb, per exemple, K sortides i representar-les verticalment. Ara feu lliscar aquesta xarxa neuronal per tota la imatge, com a resultat, obtindrem una altra imatge amb diferents amplades, alçades i profunditats. En lloc de només canals R, G i B, ara tenim més canals però menys amplada i alçada. Aquesta operació s'anomena Convolució . Si la mida del pegat és la mateixa que la de la imatge, serà una xarxa neuronal normal. A causa d'aquest petit pegat, tenim menys pesos.
Font de la imatge: Deep Learning Udacity
Ara parlem d'una mica de matemàtiques que estan implicades en tot el procés de convolució.
- Les capes de convolució consisteixen en un conjunt de filtres (o nuclis) aprenents que tenen amplades i alçades petites i la mateixa profunditat que la del volum d'entrada (3 si la capa d'entrada és una entrada d'imatge).
- Per exemple, si hem d'executar la convolució en una imatge amb dimensions 34x34x3. La mida possible dels filtres pot ser axax3, on 'a' pot ser com 3, 5 o 7, però més petit en comparació amb la dimensió de la imatge.
- Durant el pas endavant, fem lliscar cada filtre per tot el volum d'entrada pas a pas on s'anomena cada pas gambada (que pot tenir un valor de 2, 3 o fins i tot 4 per a imatges d'alta dimensió) i calculeu el producte puntual entre els pesos del nucli i el pegat a partir del volum d'entrada.
- A mesura que llisquem els nostres filtres, obtindrem una sortida 2-D per a cada filtre i, com a resultat, els apilarem, obtindrem un volum de sortida amb una profunditat igual al nombre de filtres. La xarxa aprendrà tots els filtres.
Capes utilitzades per construir ConvNets
Una arquitectura completa de xarxes neuronals de convolució també es coneix com covnets. Un covnets és una seqüència de capes, i cada capa transforma un volum a un altre mitjançant una funció diferenciable.
Tipus de capes: conjunts de dades
Prenguem un exemple executant un covnets a una imatge de dimensió 32 x 32 x 3.
- Capes d'entrada: És la capa en què donem entrada al nostre model. A CNN, generalment, l'entrada serà una imatge o una seqüència d'imatges. Aquesta capa conté l'entrada en brut de la imatge amb 32 d'amplada, 32 d'alçada i 3 de profunditat.
- Capes convolucionals: Aquesta és la capa, que s'utilitza per extreure la característica del conjunt de dades d'entrada. Aplica un conjunt de filtres aprendre coneguts com a nuclis a les imatges d'entrada. Els filtres/nuclis són matrius més petites normalment de forma 2×2, 3×3 o 5×5. llisca per sobre de les dades d'imatge d'entrada i calcula el producte puntual entre el pes del nucli i el pegat d'imatge d'entrada corresponent. La sortida d'aquesta capa es coneix com a mapes de característiques. Suposem que utilitzem un total de 12 filtres per a aquesta capa, obtindrem un volum de sortida de dimensió 32 x 32 x 12.
- Capa d'activació: En afegir una funció d'activació a la sortida de la capa anterior, les capes d'activació afegeixen no linealitat a la xarxa. aplicarà una funció d'activació per elements a la sortida de la capa de convolució. Algunes funcions d'activació habituals són resum : màxim (0, x), Peix , RELU amb fuites , etc. El volum es manté sense canvis, per tant, el volum de sortida tindrà unes dimensions de 32 x 32 x 12.
- Capa d'agrupació: Aquesta capa s'insereix periòdicament a les covnets i la seva funció principal és reduir la mida del volum, la qual cosa fa que el càlcul redueixi ràpidament la memòria i també prevé el sobreajustament. Dos tipus comuns de capes d'agrupació són agrupació màxima i agrupació mitjana . Si fem servir una piscina màxima amb 2 x 2 filtres i stride 2, el volum resultant serà de 16x16x12.
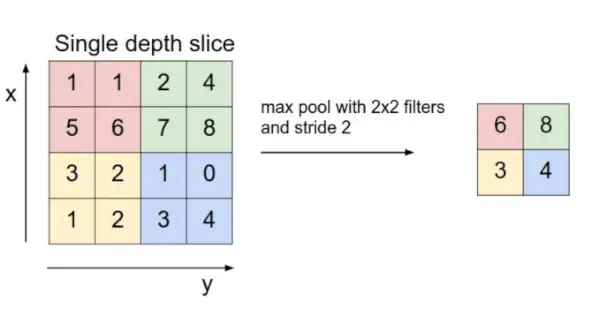
Font de la imatge: cs231n.stanford.edu
- Aplanament: Els mapes de característiques resultants s'aplanen en un vector unidimensional després de les capes de convolució i agrupació perquè es puguin passar a una capa completament enllaçada per a la categorització o la regressió.
- Capes totalment connectades: Pren l'entrada de la capa anterior i calcula la tasca final de classificació o regressió.
Font de la imatge: cs231n.stanford.edu
- Capa de sortida: La sortida de les capes completament connectades s'introdueix a una funció logística per a tasques de classificació com sigmoide o softmax que converteix la sortida de cada classe en la puntuació de probabilitat de cada classe.
Exemple:
Considerem una imatge i apliquem la capa de convolució, la capa d'activació i l'operació de capa de agrupació per extreure la característica interior.
Imatge d'entrada:
in.next java
Imatge d'entrada
Pas:
- importar les biblioteques necessàries
- establir el paràmetre
- definir el nucli
- Carregueu la imatge i dibuixeu-la.
- Reformateu la imatge
- Apliqueu l'operació de la capa de convolució i traceu la imatge de sortida.
- Apliqueu l'operació de la capa d'activació i traceu la imatge de sortida.
- Apliqueu l'operació de capa de agrupació i traceu la imatge de sortida.
Python 3
# import the necessary libraries> import> numpy as np> import> tensorflow as tf> import> matplotlib.pyplot as plt> from> itertools>import> product> > # set the param> plt.rc(>'figure'>, autolayout>=>True>)> plt.rc(>'image'>, cmap>=>'magma'>)> > # define the kernel> kernel>=> tf.constant([[>->1>,>->1>,>->1>],> >[>->1>,>8>,>->1>],> >[>->1>,>->1>,>->1>],> >])> > # load the image> image>=> tf.io.read_file(>'Ganesh.webp'plain'>)> image>=> tf.io.decode_jpeg(image, channels>=>1>)> image>=> tf.image.resize(image, size>=>[>300>,>300>])> > # plot the image> img>=> tf.squeeze(image).numpy()> plt.figure(figsize>=>(>5>,>5>))> plt.imshow(img, cmap>=>'gray'>)> plt.axis(>'off'>)> plt.title(>'Original Gray Scale image'>)> plt.show();> > > # Reformat> image>=> tf.image.convert_image_dtype(image, dtype>=>tf.float32)> image>=> tf.expand_dims(image, axis>=>0>)> kernel>=> tf.reshape(kernel, [>*>kernel.shape,>1>,>1>])> kernel>=> tf.cast(kernel, dtype>=>tf.float32)> > # convolution layer> conv_fn>=> tf.nn.conv2d> > image_filter>=> conv_fn(> >input>=>image,> >filters>=>kernel,> >strides>=>1>,># or (1, 1)> >padding>=>'SAME'>,> )> > plt.figure(figsize>=>(>15>,>5>))> > # Plot the convolved image> plt.subplot(>1>,>3>,>1>)> > plt.imshow(> >tf.squeeze(image_filter)> )> plt.axis(>'off'>)> plt.title(>'Convolution'>)> > # activation layer> relu_fn>=> tf.nn.relu> # Image detection> image_detect>=> relu_fn(image_filter)> > plt.subplot(>1>,>3>,>2>)> plt.imshow(> ># Reformat for plotting> >tf.squeeze(image_detect)> )> > plt.axis(>'off'>)> plt.title(>'Activation'>)> > # Pooling layer> pool>=> tf.nn.pool> image_condense>=> pool(>input>=>image_detect,> >window_shape>=>(>2>,>2>),> >pooling_type>=>'MAX'>,> >strides>=>(>2>,>2>),> >padding>=>'SAME'>,> >)> > plt.subplot(>1>,>3>,>3>)> plt.imshow(tf.squeeze(image_condense))> plt.axis(>'off'>)> plt.title(>'Pooling'>)> plt.show()> |
>
>
Sortida :

Imatge original en escala de grisos
Sortida
nombre de palíndrom
Avantatges de les xarxes neuronals convolucionals (CNN):
- És bo per detectar patrons i funcions en imatges, vídeos i senyals d'àudio.
- Robusta per a la translació, la rotació i la invariància d'escala.
- Formació d'extrem a extrem, sense necessitat d'extracció manual de funcions.
- Pot gestionar grans quantitats de dades i aconseguir una gran precisió.
Desavantatges de les xarxes neuronals convolucionals (CNN):
- Computacionalment car d'entrenar i requereix molta memòria.
- Pot ser propens a un sobreajustament si no s'utilitzen dades suficients o una regularització adequada.
- Requereix grans quantitats de dades etiquetades.
- La interpretabilitat és limitada, és difícil entendre què ha après la xarxa.
Preguntes freqüents (FAQ)
1: Què és una xarxa neuronal convolucional (CNN)?
Una xarxa neuronal convolucional (CNN) és un tipus de xarxa neuronal d'aprenentatge profund que és molt adequada per a l'anàlisi d'imatges i vídeos. Les CNN utilitzen una sèrie de capes de convolució i agrupació per extreure característiques d'imatges i vídeos, i després utilitzen aquestes característiques per classificar o detectar objectes o escenes.
2: Com funcionen les CNN?
Els CNN funcionen aplicant una sèrie de capes de convolució i agrupació a una imatge o vídeo d'entrada. Les capes de convolució extreuen característiques de l'entrada fent lliscar un petit filtre, o nucli, sobre la imatge o el vídeo i calculant el producte puntual entre el filtre i l'entrada. A continuació, les capes d'agrupació mostren la sortida de les capes de convolució per reduir la dimensionalitat de les dades i fer-les més eficients computacionalment.
3: Quines són algunes de les funcions d'activació habituals que s'utilitzen a les CNN?
Algunes de les funcions d'activació habituals que s'utilitzen a les CNN inclouen:
- Unitat lineal rectificada (ReLU): ReLU és una funció d'activació no saturant que és computacionalment eficient i fàcil d'entrenar.
- Unitat lineal rectificada amb fuites (Leaky ReLU): Leaky ReLU és una variant de ReLU que permet que una petita quantitat de gradient negatiu flueixi per la xarxa. Això pot ajudar a evitar que la xarxa es mori durant l'entrenament.
- Unitat lineal rectificada paramètrica (PReLU): PReLU és una generalització de Leaky ReLU que permet aprendre el pendent del gradient negatiu.
4: Quin és el propòsit d'utilitzar múltiples capes de convolució en una CNN?
L'ús de múltiples capes de convolució en una CNN permet que la xarxa aprengui funcions cada cop més complexes de la imatge o el vídeo d'entrada. Les primeres capes de convolució aprenen característiques senzilles, com ara vores i cantonades. Les capes de convolució més profundes aprenen característiques més complexes, com ara formes i objectes.
5: Quines són algunes de les tècniques de regularització habituals que s'utilitzen a les CNN?
Les tècniques de regularització s'utilitzen per evitar que les CNN sobreajustin les dades d'entrenament. Algunes tècniques de regularització habituals utilitzades a les CNN inclouen:
- Abandonament: l'abandonament elimina aleatòriament les neurones de la xarxa durant l'entrenament. Això obliga la xarxa a aprendre funcions més robustes que no depenen de cap neurona.
- Regularització L1: La regularització L1 es regularitza el valor absolut dels pesos a la xarxa. Això pot ajudar a reduir el nombre de pesos i fer que la xarxa sigui més eficient.
- Regularització L2: La regularització L2 es regularitza el quadrat dels pesos de la xarxa. Això també pot ajudar a reduir el nombre de pesos i fer que la xarxa sigui més eficient.
6: Quina diferència hi ha entre una capa de convolució i una capa d'agrupació?
Una capa de convolució extreu característiques d'una imatge o vídeo d'entrada, mentre que una capa d'agrupació redueix la mostra de la sortida de les capes de convolució. Les capes de convolució utilitzen una sèrie de filtres per extreure característiques, mentre que les capes d'agrupació utilitzen diverses tècniques per rebaixar les dades, com ara l'agrupació màxima i la agrupació mitjana.