BERT, un acrònim per a representacions de codificadors bidireccionals de transformadors , es presenta com un codi obert marc d'aprenentatge automàtic dissenyat per al regne de processament del llenguatge natural (PNL) . Originat el 2018, aquest marc va ser creat per investigadors de Google AI Language. L'article pretén explorar el arquitectura, funcionament i aplicacions de BERT .
Què és BERT?
BERT (Representacions de codificadors bidireccionals de transformadors) aprofita una xarxa neuronal basada en transformadors per entendre i generar un llenguatge semblant a l'ésser humà. BERT utilitza una arquitectura només de codificador. A l'original Arquitectura del transformador , hi ha mòduls codificador i descodificador. La decisió d'utilitzar una arquitectura només de codificador a BERT suggereix un èmfasi principal en la comprensió de les seqüències d'entrada en lloc de generar seqüències de sortida.
Enfocament bidireccional de BERT
Els models de llenguatge tradicional processen el text de manera seqüencial, ja sigui d'esquerra a dreta o de dreta a esquerra. Aquest mètode limita la consciència del model al context immediat que precedeix la paraula objectiu. BERT utilitza un enfocament bidireccional considerant tant el context esquerre com dret de les paraules d'una frase, en lloc d'analitzar el text seqüencialment, BERT mira totes les paraules d'una frase simultàniament.
Exemple: la riba està situada al _______ del riu.
En un model unidireccional, la comprensió de l'espai en blanc dependria en gran mesura de les paraules anteriors, i el model podria tenir dificultats per discernir si el banc es refereix a una institució financera o al costat del riu.
BERT, en ser bidireccional, considera simultàniament tant el context esquerre (la riba està situada al) com el dret (del riu), permetent una comprensió més matisada. Comprèn que la paraula que falta probablement està relacionada amb la ubicació geogràfica del banc, demostrant la riquesa contextual que aporta l'enfocament bidireccional.
Pre-entrenament i afinació
El model BERT passa per un procés de dos passos:
- Formació prèvia sobre grans quantitats de text sense etiquetar per aprendre incrustacions contextuals.
- Ajustament de les dades etiquetades per a específiques PNL tasques.
Formació prèvia sobre grans dades
- BERT està entrenat prèviament amb una gran quantitat de dades de text sense etiquetar. El model aprèn incrustacions contextuals, que són les representacions de paraules que tenen en compte el context que l'envolta en una frase.
- BERT es dedica a diverses tasques de formació prèvia no supervisades. Per exemple, pot aprendre a predir paraules que falten en una frase (Model de llenguatge emmascarat o tasca MLM), entendre la relació entre dues frases o predir la següent frase d'una parella.
Ajustament de les dades etiquetades
- Després de la fase prèvia a la formació, el model BERT, armat amb les seves incrustacions contextuals, s'ajusta per a tasques específiques de processament del llenguatge natural (PNL). Aquest pas adapta el model a aplicacions més específiques adaptant la seva comprensió general del llenguatge als matisos de la tasca particular.
- BERT s'ajusta amb precisió mitjançant dades etiquetades específiques per a les tasques posteriors d'interès. Aquestes tasques poden incloure anàlisi de sentiments, preguntes i respostes, reconeixement de l'entitat anomenada , o qualsevol altra aplicació de PNL. Els paràmetres del model s'ajusten per optimitzar el seu rendiment per als requisits particulars de la tasca en qüestió.
L'arquitectura unificada de BERT li permet adaptar-se a diverses tasques posteriors amb modificacions mínimes, la qual cosa la converteix en una eina versàtil i altament eficaç en comprensió del llenguatge natural i processament.
Com funciona BERT?
BERT està dissenyat per generar un model de llenguatge, de manera que només s'utilitza el mecanisme codificador. La seqüència de fitxes s'alimenta al codificador del transformador. Aquests testimonis s'incrusten primer en vectors i després es processen a la xarxa neuronal. La sortida és una seqüència de vectors, cadascun corresponent a un testimoni d'entrada, proporcionant representacions contextualitzades.
Quan s'entrenen models lingüístics, definir un objectiu de predicció és un repte. Molts models prediuen la paraula següent en una seqüència, que és un enfocament direccional i pot limitar l'aprenentatge del context. BERT aborda aquest repte amb dues estratègies de formació innovadores:
- Model de llenguatge emmascarat (MLM)
- Predicció de la següent frase (NSP)
1. Model de llenguatge emmascarat (MLM)
En el procés d'entrenament previ de BERT, una part de les paraules de cada seqüència d'entrada s'emmascara i el model s'entrena per predir els valors originals d'aquestes paraules emmascarades en funció del context proporcionat per les paraules circumdants.
En termes senzills,
- Paraules d'emmascarament: Abans que BERT aprengui de les frases, amaga algunes paraules (al voltant del 15%) i les substitueix per un símbol especial, com ara [MÀSCARA].
- Endevinar paraules amagades: La feina de BERT és esbrinar quines són aquestes paraules ocultes mirant les paraules que les envolten. És com un joc d'endevinar on falten algunes paraules, i BERT intenta omplir els buits.
- Com aprèn BERT:
- BERT afegeix una capa especial a la part superior del seu sistema d'aprenentatge per fer aquestes conjectures. A continuació, comprova quina proximitat estan les seves conjectures de les paraules ocultes reals.
- Ho fa convertint les seves conjectures en probabilitats, dient, crec que aquesta paraula és X, i n'estic molt segur.
- Especial atenció a les paraules amagades
- L'objectiu principal de BERT durant l'entrenament és encertar aquestes paraules ocultes. Es preocupa menys de predir les paraules que no s'amaguen.
- Això es deu al fet que el veritable repte és esbrinar les parts que falten, i aquesta estratègia ajuda a BERT a ser realment bo per entendre el significat i el context de les paraules.
En termes tècnics,
- BERT afegeix una capa de classificació a la part superior de la sortida del codificador. Aquesta capa és crucial per predir les paraules emmascarades.
- Els vectors de sortida de la capa de classificació es multipliquen per la matriu d'incrustació, transformant-los en la dimensió de vocabulari. Aquest pas ajuda a alinear les representacions predites amb l'espai de vocabulari.
- La probabilitat de cada paraula del vocabulari es calcula mitjançant el Funció d'activació de SoftMax . Aquest pas genera una distribució de probabilitat sobre tot el vocabulari per a cada posició emmascarada.
- La funció de pèrdua utilitzada durant l'entrenament només considera la predicció dels valors emmascarats. El model es penalitza per la desviació entre les seves prediccions i els valors reals de les paraules emmascarades.
- El model convergeix més lentament que els models direccionals. Això es deu al fet que, durant l'entrenament, BERT només es preocupa de predir els valors emmascarats, ignorant la predicció de les paraules no emmascarades. L'augment de la consciència del context aconseguit mitjançant aquesta estratègia compensa la convergència més lenta.
2. Predicció de la següent frase (NSP)
BERT prediu si la segona frase està connectada amb la primera. Això es fa transformant la sortida del testimoni [CLS] en un vector en forma de 2 × 1 mitjançant una capa de classificació, i després calculant la probabilitat de si la segona frase segueix la primera utilitzant SoftMax.
- En el procés d'entrenament, BERT aprèn a entendre la relació entre parells d'oracions, predint si la segona frase segueix la primera en el document original.
- El 50% dels parells d'entrada tenen la segona frase com a frase posterior al document original, i l'altre 50% tenen una frase escollida a l'atzar.
- Per ajudar el model a distingir entre parells d'oracions connectats i desconnectats. L'entrada es processa abans d'entrar al model:
- S'insereix un testimoni [CLS] al començament de la primera frase i un testimoni [SEP] al final de cada frase.
- S'afegeix una frase incrustada que indica la frase A o la frase B a cada testimoni.
- Una incrustació posicional indica la posició de cada testimoni en la seqüència.
- BERT prediu si la segona frase està connectada amb la primera. Això es fa transformant la sortida del testimoni [CLS] en un vector en forma de 2 × 1 mitjançant una capa de classificació, i després calculant la probabilitat de si la segona frase segueix la primera utilitzant SoftMax.
Durant l'entrenament del model BERT, el Masked LM i la Next Sentence Prediction s'entrenen conjuntament. El model pretén minimitzar la funció de pèrdua combinada de Masked LM i Next Sentence Prediction, donant lloc a un model de llenguatge robust amb capacitats millorades per comprendre el context dins de les frases i les relacions entre frases.
Per què entrenar junts Masked LM i Next Sentence Prediction?
Masked LM ajuda a BERT a entendre el context dins d'una frase i Predicció de la següent frase ajuda a BERT a entendre la connexió o relació entre parells d'oracions. Per tant, entrenar les dues estratègies juntes garanteix que BERT aprengui una comprensió àmplia i completa del llenguatge, capturant tant els detalls dins de les frases com el flux entre les frases.
Arquitecturas BERT
L'arquitectura de BERT és un codificador de transformador bidireccional multicapa que és força similar al model de transformador. Una arquitectura de transformador és una xarxa de codificador-descodificador que utilitza autoatenció al costat del codificador i atenció al costat del descodificador.
- BERTBASEté 1 2 capes a la pila de codificadors mentre que BERTGRANté 24 capes a la pila de codificadors . Aquests són més que l'arquitectura de Transformer descrita al document original ( 6 capes de codificació ).
- Les arquitectures BERT (BASE i LARGE) també tenen xarxes de feedforward més grans (768 i 1024 unitats ocultes respectivament) i més caps d'atenció (12 i 16 respectivament) que l'arquitectura Transformer suggerida al document original. Conté 512 unitats ocultes i 8 caps d'atenció .
- BERTBASEconté 110 milions de paràmetres mentre que BERTGRANté 340M de paràmetres.

Arquitectura BERT BASE i BERT GRAN.
Aquest model pren el CLS primer testimoni com a entrada, després va seguit d'una seqüència de paraules com a entrada. Aquí CLS és un testimoni de classificació. A continuació, passa l'entrada a les capes anteriors. Cada capa s'aplica autoatenció i passa el resultat a través d'una xarxa de feedforward després de passar al següent codificador. El model genera un vector de mida oculta ( 768 per BERT BASE). Si volem treure un classificador d'aquest model podem prendre la sortida corresponent al testimoni CLS.
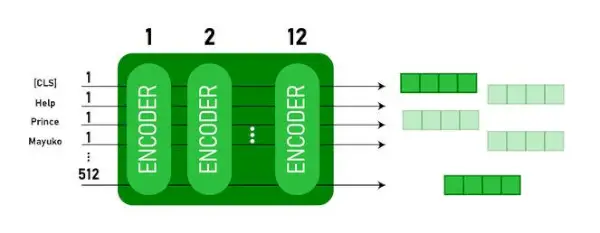
Sortida BERT com a incrustacions
Ara, aquest vector entrenat es pot utilitzar per realitzar una sèrie de tasques com la classificació, la traducció, etc. Per exemple, el paper aconsegueix grans resultats només utilitzant una sola capa Xarxa Neural sobre el model BERT en la tasca de classificació.
Com utilitzar el model BERT a la PNL?
BERT es pot utilitzar per a diverses tasques de processament del llenguatge natural (NLP), com ara:
1. Tasca de classificació
- BERT es pot utilitzar per a tasques de classificació com anàlisi de sentiments , l'objectiu és classificar el text en diferents categories (positiu/negatiu/neutre), BERT es pot utilitzar afegint una capa de classificació a la part superior de la sortida del Transformer per al testimoni [CLS].
- El testimoni [CLS] representa la informació agregada de tota la seqüència d'entrada. Aquesta representació agrupada es pot utilitzar com a entrada per a una capa de classificació per fer prediccions per a la tasca específica.
2. Resposta a preguntes
- En les tasques de resposta de preguntes, on el model és necessari per localitzar i marcar la resposta dins d'una seqüència de text determinada, es pot entrenar BERT per a aquest propòsit.
- BERT està entrenat per respondre preguntes aprenent dos vectors addicionals que marquen l'inici i el final de la resposta. Durant l'entrenament, el model rep preguntes i passatges corresponents, i aprèn a predir les posicions inicial i final de la resposta dins del passatge.
3. Reconeixement d'entitats anomenades (NER)
- BERT es pot utilitzar per a NER, on l'objectiu és identificar i classificar entitats (per exemple, Persona, Organització, Data) en una seqüència de text.
- Un model NER basat en BERT s'entrena prenent el vector de sortida de cada testimoni del Transformer i introduint-lo a una capa de classificació. La capa prediu l'etiqueta d'entitat anomenada per a cada testimoni, indicant el tipus d'entitat que representa.
Com tokenitzar i codificar text amb BERT?
Per tokenitzar i codificar text amb BERT, farem servir la biblioteca 'transformador' de Python.
Comandament per instal·lar transformadors:
!pip install transformers>
- Carregarem el tokenize BERT preentrenat amb un vocabulari en majúscules utilitzant BertTokenizer.from_pretrained(bert-base-cased) .
- tokenizer.encode(text) tokenitza el text d'entrada i el converteix en una seqüència d'ID de testimoni.
- imprimir (identificadors de testimoni:, codificació) imprimeix els ID de testimoni obtinguts després de la codificació.
- tokenizer.convert_ids_to_tokens (codificació) torna a convertir els identificadors de testimoni als seus corresponents.
- imprimir (Fitxas:, fitxes) imprimeix les fitxes obtingudes després de convertir els identificadors de testimonis
Python 3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
Sortida:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> El tokenizer.encode mètode afegeix l'especial [CLS] – classificació i [SEP] – separador fitxes al principi i al final de la seqüència codificada.
Aplicació de BERT
BERT s'utilitza per a:
- Representació del text: BERT s'utilitza per generar incrustacions de paraules o representació de paraules en una frase.
- Reconeixement d'entitats anomenades (NER) : BERT es pot ajustar per a tasques de reconeixement d'entitats amb nom, on l'objectiu és identificar entitats com ara noms de persones, organitzacions, ubicacions, etc., en un text determinat.
- Classificació del text: BERT s'utilitza àmpliament per a tasques de classificació de text, com ara l'anàlisi de sentiments, la detecció de correu brossa i la categorització de temes. Ha demostrat un excel·lent rendiment en la comprensió i la classificació del context de les dades textuals.
- Sistemes de preguntes i respostes: BERT s'ha aplicat als sistemes de resposta a preguntes, on el model s'entrena per entendre el context d'una pregunta i proporcionar respostes rellevants. Això és especialment útil per a tasques com la comprensió lectora.
- Traducció automàtica: Les integracions contextuals de BERT es poden aprofitar per millorar els sistemes de traducció automàtica. El model captura els matisos del llenguatge que són crucials per a una traducció precisa.
- Resum del text: BERT es pot utilitzar per al resum abstractiu de textos, on el model genera resums concisos i significatius de textos més llargs mitjançant la comprensió del context i la semàntica.
- IA conversacional: BERT s'utilitza per construir sistemes d'IA conversacionals, com ara chatbots, assistents virtuals i sistemes de diàleg. La seva capacitat per comprendre el context el fa eficaç per entendre i generar respostes en llenguatge natural.
- Similitud semàntica: Les incrustacions BERT es poden utilitzar per mesurar la similitud semàntica entre frases o documents. Això és valuós en tasques com la detecció de duplicats, la identificació de paràfrasis i la recuperació d'informació.
BERT vs GPT
La diferència entre BERT i GPT són les següents:
| BERT | GPT | |
|---|---|---|
| Arquitectura | BERT està dissenyat per a l'aprenentatge de la representació bidireccional. Utilitza un objectiu model de llenguatge emmascarat, on prediu paraules que falten en una frase en funció del context esquerre i dret. | GPT, d'altra banda, està dissenyat per al modelatge de llenguatge generatiu. Prediu la paraula següent en una frase donat el context anterior, utilitzant un enfocament autoregressiu unidireccional. |
| Objectius previs a la formació | BERT s'entrena prèviament mitjançant un objectiu del model de llenguatge emmascarat i la predicció de la següent frase. Se centra a capturar el context bidireccional i entendre les relacions entre les paraules d'una frase. | GPT està entrenat prèviament per predir la paraula següent en una frase, la qual cosa anima el model a aprendre una representació coherent del llenguatge i generar seqüències rellevants contextualment. |
| Comprensió del context | BERT és eficaç per a tasques que requereixen una comprensió profunda del context i les relacions dins d'una frase, com ara la classificació de text, el reconeixement d'entitats amb nom i la resposta a preguntes. | GPT és fort per generar text coherent i rellevant per al context. Sovint s'utilitza en tasques creatives, sistemes de diàleg i tasques que requereixen la generació de seqüències de llenguatge natural. |
| Tipus de tasques i casos d'ús
| S'utilitza habitualment en tasques com la classificació de text, el reconeixement d'entitats amb nom, l'anàlisi de sentiments i la resposta a preguntes. | S'aplica a tasques com la generació de text, sistemes de diàleg, resum i escriptura creativa. |
| Ajustament fi vs aprenentatge de pocs tirs | Sovint, BERT s'ajusta amb precisió a tasques posteriors específiques amb dades etiquetades per adaptar les seves representacions prèviament entrenades a la tasca en qüestió. | GPT està dissenyat per dur a terme un aprenentatge de pocs cops, on es pot generalitzar a tasques noves amb dades d'entrenament específiques de tasques mínimes. |
Comproveu també:
- Classificació de sentiments mitjançant BERT
- Com generar incrustació de paraules amb BERT?
- Model BART per a la compleció automàtica de text en PNL
- Classificació de comentaris tòxics mitjançant BERT
- Predicció de la següent frase utilitzant BERT
Preguntes freqüents (FAQ)
P. Per a què serveix BERT?
BERT s'utilitza per realitzar tasques de PNL com la representació de text, el reconeixement d'entitats amb nom, la classificació de text, els sistemes de preguntes i respostes, la traducció automàtica, el resum de text i molt més.
P. Quins són els avantatges del model BERT?
El model lingüístic BERT destaca per la seva àmplia formació prèvia en múltiples idiomes, oferint una àmplia cobertura lingüística en comparació amb altres models. Això fa que BERT sigui especialment avantatjós per a projectes no basats en anglès, ja que proporciona representacions contextuals robustes i comprensió semàntica en una àmplia gamma d'idiomes, millorant la seva versatilitat en aplicacions multilingües.
P. Com funciona BERT per a l'anàlisi de sentiments?
BERT destaca en l'anàlisi de sentiments aprofitant el seu aprenentatge de representació bidireccional per capturar matisos contextuals, significats semàntics i estructures sintàctiques dins d'un text determinat. Això permet a BERT entendre el sentiment expressat en una frase tenint en compte les relacions entre paraules, donant com a resultat resultats d'anàlisi de sentiments molt eficaços.
10 milions
P. Google es basa en BERT?
BERT i RankBrain són components de l'algorisme de cerca de Google per processar consultes i contingut de pàgines web per obtenir una millor comprensió per millorar els resultats de la cerca.