Els fulls d'Excel són molt instintius i fàcils d'utilitzar, cosa que els fa ideals per manipular grans conjunts de dades, fins i tot per a gent menys tècnica. Si esteu buscant llocs per aprendre a manipular i automatitzar coses en fitxers Excel Python , no miris més enllà. Estàs al lloc correcte.
En aquest article, aprendràs a utilitzar-lo Pandes per treballar amb fulls de càlcul Excel. En aquest article aprendrem sobre:
- Llegeix Fitxer Excel utilitzant Pandas a Python
- Instal·lació i importació de Pandas
- Llegir diversos fulls d'Excel amb Pandas
- Aplicació de diferents funcions Pandas
Llegint un fitxer Excel amb Pandas a Python
Instal·lació de Pandas
Per instal·lar Pandas a Python, podem utilitzar l'ordre següent a l'indicador d'ordres:
pip install pandas>
Per instal·lar Pandas a Anaconda, podem utilitzar l'ordre següent a Anaconda Terminal:
conda install pandas>
Importació de pandes
En primer lloc, hem d'importar el mòdul Pandas que es pot fer executant l'ordre:
Python 3
import> pandas as pd> |
>
>
Fitxer d'entrada: Suposem que el fitxer Excel té aquest aspecte
Full 1:

Fitxa 1
Full 2:
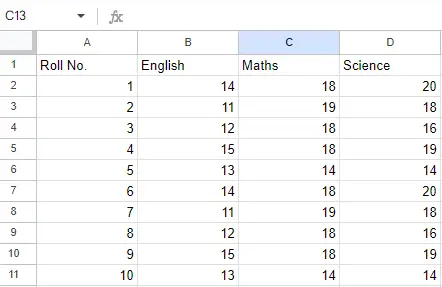
Fitxa 2
Ara podem importar el fitxer Excel mitjançant la funció read_excel a Pandas per llegir el fitxer Excel mitjançant Pandas a Python. La segona declaració llegeix les dades d'Excel i les emmagatzema en un marc de dades pandas que està representat per la variable newData.
Python 3
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
travessa de comanda prèvia
>
Sortida:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Carregant diversos fulls mitjançant el mètode Concat().
Si hi ha diversos fulls al llibre d'Excel, l'ordre importarà dades del primer full. Per fer un marc de dades amb tots els fulls del llibre de treball, el mètode més fàcil és crear diferents marcs de dades per separat i després concatenar-los. El mètode read_excel pren els arguments sheet_name i index_col on podem especificar el full del qual s'ha de fer el marc i index_col especifica la columna del títol, tal com es mostra a continuació:
Exemple:
La tercera afirmació concatena ambdós fulls. Ara per comprovar tot el marc de dades, simplement podem executar la següent comanda:
Python 3
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
Sortida:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Mètodes Head() i Tail() a Pandas
Per veure 5 columnes des de la part superior i inferior del marc de dades, podem executar l'ordre. Això cap () i cua () El mètode també pren arguments com a números per al nombre de columnes que es mostren.
Python 3
print>(newData.head())> print>(newData.tail())> |
>
>
Sortida:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Mètode Shape().
El mètode shape(). es pot utilitzar per veure el nombre de files i columnes del marc de dades de la manera següent:
Python 3
newData.shape> |
>
>
Sortida:
(20, 3)>
Mètode Sort_values() a Pandas
Si alguna columna conté dades numèriques, podem ordenar-la mitjançant l' valors_ordenar() mètode en pandes de la següent manera:
Python 3
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
Ara, suposem que volem els 5 valors principals de la columna ordenada, podem utilitzar el mètode head() aquí:
Python 3
sorted_column.head(>5>)> |
>
>
Sortida:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
Ho podem fer amb qualsevol columna numèrica del marc de dades tal com es mostra a continuació:
Python 3
newData[>'Maths'>].head()> |
>
>
Sortida:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
Mètode Pandas Describe().
Ara, suposem que les nostres dades són majoritàriament numèriques. Podem obtenir la informació estadística com la mitjana, el màxim, el mínim, etc. sobre el marc de dades mitjançant el descriure () mètode tal com es mostra a continuació:
Python 3
newData.describe()> |
>
>
Sortida:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
Això també es pot fer per separat per a totes les columnes numèriques mitjançant l'ordre següent:
Python 3
newData[>'English'>].mean()> |
>
>
Sortida:
14.3>
També es poden calcular altres dades estadístiques mitjançant els mètodes respectius. Igual que a Excel, també es poden aplicar fórmules i es poden crear columnes calculades de la següent manera:
Python 3
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
>
>
introduint una cadena en java
Sortida:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
Després d'operar amb les dades del marc de dades, podem exportar les dades de nou a un fitxer Excel mitjançant el mètode to_excel. Per a això, hem d'especificar un fitxer Excel de sortida on s'han d'escriure les dades transformades, tal com es mostra a continuació:
Python 3
newData.to_excel(>'Output File.xlsx'>)> |
>
>
Sortida:
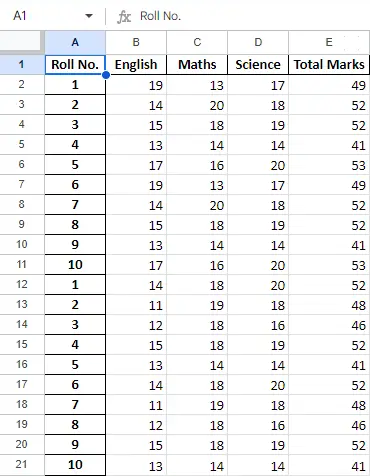
Fitxa final