Python és un llenguatge fantàstic per fer anàlisi de dades, principalment a causa del fantàstic ecosistema de dades centrades. Python paquets. Pandes és un d'aquests paquets i facilita molt la importació i l'anàlisi de dades.
Pandas DataFrame significa ()
Pandes dataframe.mean() La funció retorna la mitjana dels valors de l'eix sol·licitat. Si el mètode s'aplica a un objecte de sèrie pandas, llavors el mètode retorna un valor escalar que és el valor mitjà de totes les observacions del Pandas Dataframe . Si el mètode s'aplica a un objecte Pandas Dataframe, el mètode retorna a Sèrie Pandas objecte que conté la mitjana dels valors sobre l'eix especificat.
Sintaxi: DataFrame.mean(axis=0, skipna=True, level=None, numeric_only=False, **kwargs)
Paràmetres:
- eix: {índex (0), columnes (1)}
- comanda: Exclou els valors NA/nuls quan calculeu el resultat
- nivell: Si l'eix és un MultiIndex (jeràrquic), compta al llarg d'un nivell particular, col·lapsant-se en una sèrie
- només_numèric: Inclou només columnes float, int i booleanes. Si Cap, intentarà utilitzar-ho tot i, a continuació, utilitzarà només dades numèriques. No implementat per a la sèrie.
Devolucions: mitjana: sèrie o DataFrame (si s'especifica el nivell)
algorisme de cabina
Pandas DataFrame.mean() Exemples
Exemple 1:
Utilitzeu la funció mean() per trobar la mitjana de totes les observacions sobre l'eix de l'índex.
Python # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, 44, 1], 'B':[5, 2, 54, 3, 2], 'C':[20, 16, 7, 3, 8], 'D':[14, 3, 17, 2, 6]}) # Print the dataframe df> 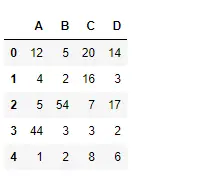
Utilitzem la funció Dataframe.mean() per trobar la mitjana sobre l'eix de l'índex.
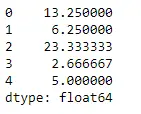
Python # Even if we do not specify axis = 0, # the method will return the mean over # the index axis by default df.mean(axis = 0)>
Sortida:
Exemple 2:
Utilitzeu la funció mean() en un Dataframe que tingui valors None. A més, trobeu la mitjana sobre l'eix de la columna.
Python # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, None, 1], 'B':[7, 2, 54, 3, None], 'C':[20, 16, 11, 3, 8], 'D':[14, 3, None, 2, 6]}) # skip the Na values while finding the mean df.mean(axis = 1, skipna = True)> Sortida: