L'aprenentatge automàtic és la branca de Intel · ligència artificial que se centra a desenvolupar models i algorismes que permetin als ordinadors aprendre de les dades i millorar l'experiència anterior sense estar programats explícitament per a cada tasca. En paraules senzilles, ML ensenya als sistemes a pensar i entendre com els humans aprenent de les dades.
En aquest article, explorarem els diferents Tipus de algorismes d'aprenentatge automàtic que són importants per a les necessitats futures. Aprenentatge automàtic generalment és un sistema d'entrenament per aprendre d'experiències passades i millorar el rendiment al llarg del temps. Aprenentatge automàtic ajuda a predir grans quantitats de dades. Ajuda a oferir resultats ràpids i precisos per obtenir oportunitats rendibles.
Tipus d'aprenentatge automàtic
Hi ha diversos tipus d'aprenentatge automàtic, cadascun amb característiques i aplicacions especials. Alguns dels principals tipus d'algorismes d'aprenentatge automàtic són els següents:
- Aprenentatge automàtic supervisat
- Aprenentatge automàtic no supervisat
- Aprenentatge automàtic semi-supervisat
- Aprenentatge de reforç
Tipus d'aprenentatge automàtic
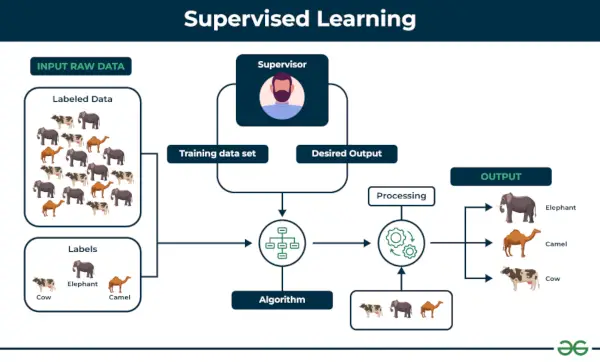
1. Aprenentatge automàtic supervisat
Aprenentatge supervisat es defineix com quan un model s'entrena en a Conjunt de dades etiquetat . Els conjunts de dades etiquetats tenen paràmetres d'entrada i de sortida. En Aprenentatge supervisat Els algorismes aprenen a mapar punts entre entrades i sortides correctes. Té conjunts de dades de formació i validació etiquetats.
Aprenentatge supervisat
Entenem-ho amb l'ajuda d'un exemple.
Exemple: Penseu en un escenari en què haureu de crear un classificador d'imatges per diferenciar entre gats i gossos. Si introduïu els conjunts de dades d'imatges etiquetades de gossos i gats a l'algorisme, la màquina aprendrà a classificar entre un gos o un gat a partir d'aquestes imatges etiquetades. Quan introduïm imatges noves de gossos o gats que mai no ha vist abans, utilitzarà els algorismes apresos i predirà si és un gos o un gat. Així és com aprenentatge supervisat funciona, i això és particularment una classificació d'imatges.
Hi ha dues categories principals d'aprenentatge supervisat que s'esmenten a continuació:
- Classificació
- Regressió
Classificació
Classificació tracta de predir categòrica variables objectiu, que representen classes o etiquetes discretes. Per exemple, classificar els correus electrònics com a correu brossa o no, o predir si un pacient té un alt risc de patir malalties del cor. Els algorismes de classificació aprenen a assignar les característiques d'entrada a una de les classes predefinides.
Aquests són alguns algorismes de classificació:
eol en python
- Regressió logística
- Màquina vectorial de suport
- Bosc aleatori
- Arbre de decisions
- K-Veïns més propers (KNN)
- Bayes ingenu
Regressió
Regressió , en canvi, s'ocupa de la predicció contínua variables objectiu, que representen valors numèrics. Per exemple, predir el preu d'una casa en funció de la seva mida, ubicació i comoditats, o pronosticar les vendes d'un producte. Els algorismes de regressió aprenen a mapar les característiques d'entrada a un valor numèric continu.
Aquests són alguns algorismes de regressió:
- Regressió lineal
- Regressió polinòmica
- Regression de Ridge
- Regressió del lazo
- Arbre de decisions
- Bosc aleatori
Avantatges de l'aprenentatge automàtic supervisat
- Aprenentatge supervisat els models poden tenir una gran precisió a mesura que s'entrenen dades etiquetades .
- El procés de presa de decisions en models d'aprenentatge supervisat sovint és interpretable.
- Sovint es pot utilitzar en models pre-entrenats, cosa que estalvia temps i recursos quan es desenvolupen nous models des de zero.
Inconvenients de l'aprenentatge automàtic supervisat
- Té limitacions a l'hora de conèixer patrons i pot lluitar amb patrons no vists o inesperats que no estan presents a les dades d'entrenament.
- Pot ser molt llarg i costós, ja que depèn etiquetat només dades.
- Pot conduir a generalitzacions pobres basades en dades noves.
Aplicacions de l'aprenentatge supervisat
L'aprenentatge supervisat s'utilitza en una gran varietat d'aplicacions, com ara:
- Classificació de la imatge : identifiqueu objectes, cares i altres característiques a les imatges.
- Processament del llenguatge natural: Extreu informació del text, com ara sentiments, entitats i relacions.
- Reconeixement de veu : Converteix el llenguatge parlat en text.
- Sistemes de recomanació : Feu recomanacions personalitzades als usuaris.
- Analítica predictiva : prediu els resultats, com ara les vendes, la rotació de clients i els preus de les accions.
- Diagnòstic mèdic : Detectar malalties i altres afeccions mèdiques.
- Detecció de frau : Identificar transaccions fraudulentes.
- Vehicles autònoms : Reconèixer i respondre als objectes de l'entorn.
- Detecció de correu brossa : classifica els correus electrònics com a correu brossa o no com a correu brossa.
- Control de qualitat en la fabricació : Inspeccioneu els productes per detectar defectes.
- Puntuació de crèdit : Avaluar el risc que un prestatari no s'acrediti amb un préstec.
- Jocs : Reconèixer personatges, analitzar el comportament dels jugadors i crear NPC.
- Atenció al client : Automatitzar les tasques d'atenció al client.
- Previsió meteorològica : Feu prediccions de temperatura, precipitació i altres paràmetres meteorològics.
- Analítica esportiva : Analitzeu el rendiment dels jugadors, feu prediccions de jocs i optimitzeu estratègies.
2. Aprenentatge automàtic no supervisat
Aprenentatge no supervisat L'aprenentatge no supervisat és un tipus de tècnica d'aprenentatge automàtic en què un algorisme descobreix patrons i relacions mitjançant dades sense etiquetar. A diferència de l'aprenentatge supervisat, l'aprenentatge no supervisat no implica proporcionar a l'algorisme sortides objectiu etiquetades. L'objectiu principal de l'aprenentatge no supervisat és sovint descobrir patrons, similituds o grups ocults dins de les dades, que després es poden utilitzar per a diversos propòsits, com ara l'exploració de dades, la visualització, la reducció de la dimensionalitat i molt més.
if else declaració en java
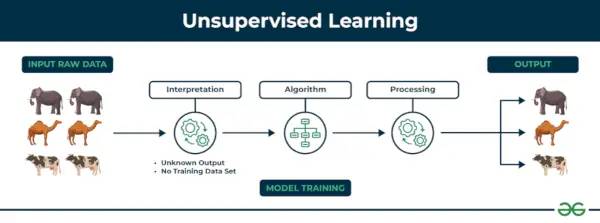
Aprenentatge no supervisat
Entenem-ho amb l'ajuda d'un exemple.
Exemple: Tingueu en compte que teniu un conjunt de dades que conté informació sobre les compres que heu fet a la botiga. Mitjançant la agrupació, l'algoritme pot agrupar el mateix comportament de compra entre vostè i altres clients, cosa que revela clients potencials sense etiquetes predefinides. Aquest tipus d'informació pot ajudar les empreses a aconseguir clients objectiu i a identificar els valors atípics.
Hi ha dues categories principals d'aprenentatge no supervisat que s'esmenten a continuació:
- Agrupació
- Associació
Agrupació
Agrupació és el procés d'agrupar punts de dades en clústers en funció de la seva similitud. Aquesta tècnica és útil per identificar patrons i relacions en dades sense necessitat d'exemples etiquetats.
Aquests són alguns algorismes de agrupació:
- Algorisme de agrupació K-Means
- Algorisme de desplaçament mitjà
- Algoritme DBSCAN
- Anàlisi de components principals
- Anàlisi independent de components
Associació
Aprendre les regles d'associació ing és una tècnica per descobrir relacions entre elements d'un conjunt de dades. Identifica regles que indiquen que la presència d'un element implica la presència d'un altre element amb una probabilitat específica.
Aquests són alguns algorismes d'aprenentatge de regles d'associació:
- Algorisme a priori
- Brillar
- Algoritme de creixement FP
Avantatges de l'aprenentatge automàtic no supervisat
- Ajuda a descobrir patrons ocults i diverses relacions entre les dades.
- S'utilitza per a tasques com ara segmentació de clients, detecció d'anomalies, i exploració de dades .
- No requereix dades etiquetades i redueix l'esforç de l'etiquetatge de dades.
Desavantatges de l'aprenentatge automàtic no supervisat
- Sense utilitzar etiquetes, pot ser difícil predir la qualitat de la sortida del model.
- La interpretabilitat del clúster pot no ser clara i no tenir interpretacions significatives.
- Té tècniques com codificadors automàtics i reducció de la dimensionalitat que es poden utilitzar per extreure característiques significatives de dades en brut.
Aplicacions de l'aprenentatge no supervisat
Aquestes són algunes de les aplicacions habituals de l'aprenentatge no supervisat:
- Agrupació : agrupa punts de dades similars en clústers.
- Detecció d'anomalies : Identificar valors atípics o anomalies en les dades.
- Reducció de la dimensionalitat : Reduir la dimensionalitat de les dades tot conservant la seva informació essencial.
- Sistemes de recomanació : suggereix productes, pel·lícules o contingut als usuaris en funció del seu comportament històric o preferències.
- Modelatge de temes : Descobriu temes latents dins d'una col·lecció de documents.
- Estimació de la densitat : Estimar la funció de densitat de probabilitat de les dades.
- Compressió d'imatge i vídeo : Redueix la quantitat d'emmagatzematge necessària per al contingut multimèdia.
- Preprocessament de dades : Ajuda amb tasques de preprocessament de dades, com ara la neteja de dades, l'imputació de valors que falten i l'escala de dades.
- Anàlisi de cistella de mercat : Descobrir associacions entre productes.
- Anàlisi de dades genòmiques : Identificar patrons o agrupar gens amb perfils d'expressió similars.
- Segmentació d'imatges : Segmenta les imatges en regions significatives.
- Detecció de comunitats a les xarxes socials : Identificar comunitats o grups d'individus amb interessos o connexions similars.
- Anàlisi del comportament del client : Descobriu patrons i estadístiques per obtenir millors recomanacions de màrqueting i productes.
- Recomanació de contingut : classifica i etiqueta contingut per facilitar la recomanació d'articles similars als usuaris.
- Anàlisi exploratòria de dades (EDA) : Exploreu les dades i obteniu informació abans de definir tasques específiques.
3. Aprenentatge semitutelat
Aprenentatge semitutelat és un algorisme d'aprenentatge automàtic que funciona entre supervisats i no supervisats aprenentatge, de manera que utilitza tots dos etiquetats i sense etiquetar dades. És especialment útil quan l'obtenció de dades etiquetades és costosa, requereix temps o requereix molts recursos. Aquest enfocament és útil quan el conjunt de dades és car i requereix temps. L'aprenentatge semi-supervisat s'escull quan les dades etiquetades requereixen habilitats i recursos rellevants per formar-se o aprendre d'ell.
Utilitzem aquestes tècniques quan estem tractant amb dades que estan una mica etiquetades i la resta gran part no està etiquetada. Podem utilitzar les tècniques no supervisades per predir etiquetes i després alimentar aquestes etiquetes a tècniques supervisades. Aquesta tècnica s'aplica sobretot en el cas de conjunts de dades d'imatge on normalment totes les imatges no estan etiquetades.
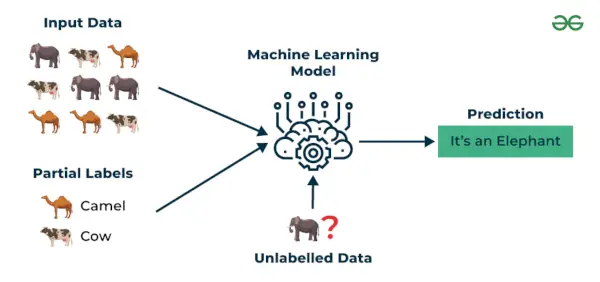
Aprenentatge semitutelat
llocs com coomeet
Entenem-ho amb l'ajuda d'un exemple.
Exemple : Tingueu en compte que estem construint un model de traducció d'idiomes, tenir traduccions etiquetades per a cada parell de frases pot suposar una gran quantitat de recursos. Permet que els models aprenguin de parelles de frases etiquetades i no etiquetades, fent-les més precises. Aquesta tècnica ha comportat millores importants en la qualitat dels serveis de traducció automàtica.
Tipus de mètodes d'aprenentatge semi-supervisat
Hi ha diferents mètodes d'aprenentatge semi-supervisat, cadascun amb les seves pròpies característiques. Alguns dels més comuns inclouen:
- Aprenentatge semisupervisat basat en gràfics: Aquest enfocament utilitza un gràfic per representar les relacions entre els punts de dades. A continuació, el gràfic s'utilitza per propagar etiquetes des dels punts de dades etiquetats als punts de dades sense etiquetar.
- Propagació de l'etiqueta: Aquest enfocament propaga de manera iterativa les etiquetes des dels punts de dades etiquetats als punts de dades no etiquetats, en funció de les similituds entre els punts de dades.
- Formació conjunta: Aquest enfocament entrena dos models diferents d'aprenentatge automàtic en diferents subconjunts de dades sense etiquetar. Els dos models s'utilitzen llavors per etiquetar les prediccions de l'altre.
- Autoformació: Aquest enfocament entrena un model d'aprenentatge automàtic sobre les dades etiquetades i després utilitza el model per predir les etiquetes de les dades sense etiquetar. A continuació, el model es torna a formar a les dades etiquetades i les etiquetes previstes per a les dades sense etiquetar.
- Xarxes adversàries generatives (GAN) : Els GAN són un tipus d'algorisme d'aprenentatge profund que es pot utilitzar per generar dades sintètiques. Els GAN es poden utilitzar per generar dades sense etiquetar per a l'aprenentatge semi-supervisat entrenant dues xarxes neuronals, un generador i un discriminador.
Avantatges de l'aprenentatge automàtic semi-supervisat
- Condueix a una millor generalització en comparació amb aprenentatge supervisat, ja que pren dades etiquetades i no etiquetades.
- Es pot aplicar a una àmplia gamma de dades.
Inconvenients de l'aprenentatge automàtic semi-supervisat
- Semi supervisat Els mètodes poden ser més complexos d'implementar en comparació amb altres enfocaments.
- Encara en requereix algun dades etiquetades que potser no sempre estan disponibles o fàcils d'aconseguir.
- Les dades sense etiqueta poden afectar el rendiment del model en conseqüència.
Aplicacions de l'aprenentatge semitutelat
A continuació es mostren algunes aplicacions habituals de l'aprenentatge semisupervisat:
- Classificació d'imatges i reconeixement d'objectes : milloreu la precisió dels models combinant un conjunt petit d'imatges etiquetades amb un conjunt més gran d'imatges sense etiquetar.
- Processament del llenguatge natural (PNL) : milloreu el rendiment dels models i classificadors de llenguatge combinant un petit conjunt de dades de text etiquetats amb una gran quantitat de text sense etiquetar.
- Reconeixement de veu: Milloreu la precisió del reconeixement de veu aprofitant una quantitat limitada de dades de parla transcrites i un conjunt més ampli d'àudio sense etiquetar.
- Sistemes de recomanació : milloreu la precisió de les recomanacions personalitzades complementant un conjunt escàs d'interaccions d'elements d'usuari (dades etiquetades) amb una gran quantitat de dades de comportament dels usuaris sense etiquetar.
- Sanitat i Imatge Mèdica : milloreu l'anàlisi d'imatges mèdiques utilitzant un petit conjunt d'imatges mèdiques etiquetades juntament amb un conjunt més gran d'imatges sense etiquetar.
4. Reforç de l'aprenentatge automàtic
Reforç de l'aprenentatge automàtic L'algoritme és un mètode d'aprenentatge que interactua amb l'entorn produint accions i descobrint errors. Prova, error i retard són les característiques més rellevants de l'aprenentatge per reforç. En aquesta tècnica, el model continua augmentant el seu rendiment mitjançant Reward Feedback per aprendre el comportament o el patró. Aquests algorismes són específics per a un problema particular, p. Cotxe de conducció automàtica de Google, AlphaGo on un bot competeix amb els humans i fins i tot amb ell mateix per obtenir cada cop millors rendiments a Go Game. Cada vegada que alimentem dades, aprenen i afegeixen les dades al seu coneixement, que són dades d'entrenament. Així, com més aprèn, millor s'entrena i, per tant, experimenta.
Aquests són alguns dels algorismes d'aprenentatge de reforç més comuns:
- Q-learning: Q-learning és un algorisme RL sense model que aprèn una funció Q, que mapeja estats amb accions. La funció Q estima la recompensa esperada de fer una acció concreta en un estat determinat.
- SARSA (Estat-Acció-Recompensa-Estat-Acció): SARSA és un altre algorisme RL sense model que aprèn una funció Q. Tanmateix, a diferència de Q-learning, SARSA actualitza la funció Q per a l'acció que es va dur a terme realment, en lloc de l'acció òptima.
- Q-learning profund : El deep Q-learning és una combinació de Q-learning i deep learning. Deep Q-learning utilitza una xarxa neuronal per representar la funció Q, que li permet aprendre relacions complexes entre estats i accions.
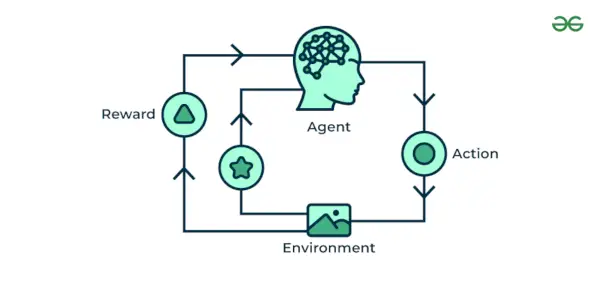
Reforç de l'aprenentatge automàtic
Entenem-ho amb l'ajuda d'exemples.
Exemple: Considera que estàs entrenant un AI agent per jugar un joc com els escacs. L'agent explora diferents moviments i rep feedback positiu o negatiu en funció del resultat. L'aprenentatge per reforç també troba aplicacions en les quals aprenen a realitzar tasques interactuant amb el seu entorn.
Tipus de reforç d'aprenentatge automàtic
Hi ha dos tipus principals d'aprenentatge per reforç:
Reforç positiu
- Recompensa l'agent per fer l'acció desitjada.
- Anima l'agent a repetir la conducta.
- Exemples: donar una delícia a un gos perquè s'asseu, donant un punt en un joc per a una resposta correcta.
Reforç negatiu
- Elimina un estímul indesitjable per fomentar un comportament desitjat.
- Desanima l'agent de repetir la conducta.
- Exemples: apagar un timbre fort quan es prem una palanca, evitant una penalització en completar una tasca.
Avantatges de l'aprenentatge automàtic de reforç
- Té una presa de decisions autònoma que s'adapta bé a les tasques i que pot aprendre a prendre una seqüència de decisions, com ara la robòtica i el joc.
- Aquesta tècnica es prefereix per aconseguir resultats a llarg termini molt difícils d'aconseguir.
- S'utilitza per resoldre problemes complexos que no es poden resoldre amb tècniques convencionals.
Inconvenients de l'aprenentatge automàtic de reforç
- Reforç de l'entrenament Els agents d'aprenentatge poden ser computacionalment costosos i consumir temps.
- L'aprenentatge de reforç no és preferible a la resolució de problemes senzills.
- Necessita moltes dades i molts càlculs, la qual cosa fa que sigui poc pràctic i costós.
Aplicacions de l'aprenentatge automàtic de reforç
Aquestes són algunes aplicacions de l'aprenentatge per reforç:
- Joc Jugant : RL pot ensenyar als agents a jugar, fins i tot a jocs complexos.
- Robòtica : RL pot ensenyar als robots a realitzar tasques de manera autònoma.
- Vehicles Autònoms : RL pot ajudar els cotxes autònoms a navegar i prendre decisions.
- Sistemes de recomanació : RL pot millorar els algorismes de recomanació aprenent les preferències de l'usuari.
- Atenció sanitària : RL es pot utilitzar per optimitzar els plans de tractament i el descobriment de fàrmacs.
- Processament del llenguatge natural (PNL) : RL es pot utilitzar en sistemes de diàleg i chatbots.
- Finances i comerç : RL es pot utilitzar per al comerç algorítmic.
- Cadena de subministrament i gestió d'inventaris : RL es pot utilitzar per optimitzar les operacions de la cadena de subministrament.
- Gestió de l'energia : RL es pot utilitzar per optimitzar el consum d'energia.
- Jocs d'IA : RL es pot utilitzar per crear NPC més intel·ligents i adaptatius als videojocs.
- Assistents personals adaptatius : RL es pot utilitzar per millorar els assistents personals.
- Realitat virtual (VR) i realitat augmentada (AR): RL es pot utilitzar per crear experiències immersives i interactives.
- Control industrial : RL es pot utilitzar per optimitzar processos industrials.
- Educació : RL es pot utilitzar per crear sistemes d'aprenentatge adaptatius.
- Agricultura : RL es pot utilitzar per optimitzar les operacions agrícoles.
Cal comprovar, el nostre article detallat sobre : Algoritmes d'aprenentatge automàtic
Conclusió
En conclusió, cada tipus d'aprenentatge automàtic té el seu propi propòsit i contribueix al paper general en el desenvolupament de capacitats de predicció de dades millorades, i té el potencial de canviar diverses indústries com ara Ciència de dades . Ajuda a gestionar la producció massiva de dades i la gestió dels conjunts de dades.
Tipus d'aprenentatge automàtic: preguntes freqüents
1. Quins són els reptes als quals s'enfronta l'aprenentatge supervisat?
Alguns dels reptes que s'enfronten a l'aprenentatge supervisat inclouen principalment abordar els desequilibris de classe, dades etiquetades d'alta qualitat i evitar l'excés d'adaptació on els models funcionen malament amb dades en temps real.
cadena d'entrada java
2. On podem aplicar l'aprenentatge supervisat?
L'aprenentatge supervisat s'utilitza habitualment per a tasques com ara l'anàlisi de correus electrònics de correu brossa, el reconeixement d'imatges i l'anàlisi de sentiments.
3. Com és el futur de les perspectives d'aprenentatge automàtic?
L'aprenentatge automàtic com a perspectiva de futur pot funcionar en àrees com l'anàlisi del temps o el clima, els sistemes sanitaris i la modelització autònoma.
4. Quins són els diferents tipus d'aprenentatge automàtic?
Hi ha tres tipus principals d'aprenentatge automàtic:
- Aprenentatge supervisat
- Aprenentatge no supervisat
- Aprenentatge de reforç
5. Quins són els algorismes d'aprenentatge automàtic més comuns?
Alguns dels algorismes d'aprenentatge automàtic més comuns inclouen:
- Regressió lineal
- Regressió logística
- Màquines vectorials de suport (SVM)
- K-veïns més propers (KNN)
- Arbres de decisió
- Boscos aleatoris
- Xarxes neuronals artificials