En el món real aprenentatge automàtic aplicacions, és comú tenir moltes característiques rellevants, però només un subconjunt d'elles pot ser observable. Quan es tracta de variables que de vegades són observables i de vegades no, és possible utilitzar els casos en què aquesta variable és visible o observada per aprendre i fer prediccions per als casos en què no és observable. Aquest enfocament sovint es coneix com a maneig de dades que falten. Mitjançant l'ús dels casos disponibles en què la variable és observable, els algorismes d'aprenentatge automàtic poden aprendre patrons i relacions a partir de les dades observades. Aquests patrons apresos es poden utilitzar per predir els valors de la variable en casos en què no es pot observar o no.
L'algorisme d'expectació-maximització es pot utilitzar per manejar situacions en què les variables són parcialment observables. Quan determinades variables són observables, podem utilitzar aquestes instàncies per aprendre i estimar-ne els valors. Aleshores, podem predir els valors d'aquestes variables en casos en què no és observable.
np.zeros
L'algoritme EM va ser proposat i nomenat en un article fonamental publicat el 1977 per Arthur Dempster, Nan Laird i Donald Rubin. El seu treball va formalitzar l'algorisme i va demostrar la seva utilitat en la modelització i estimació estadística.
L'algorisme EM és aplicable a variables latents, que són variables que no són directament observables però que es dedueixen dels valors d'altres variables observades. Aprofitant la forma general coneguda de la distribució de probabilitat que regeix aquestes variables latents, l'algoritme EM pot predir els seus valors.
L'algoritme EM serveix com a base per a molts algorismes de clúster no supervisats en el camp de l'aprenentatge automàtic. Proporciona un marc per trobar els paràmetres de màxima probabilitat local d'un model estadístic i inferir variables latents en els casos en què les dades falten o estan incompletes.
Algorisme Expectació-Maximització (EM).
L'algorisme d'expectació-maximització (EM) és un mètode d'optimització iteratiu que combina diferents aprenentatge automàtic algorismes per trobar la màxima probabilitat o estimacions posteriors màximes de paràmetres en models estadístics que involucren variables latents no observades. L'algoritme EM s'utilitza habitualment per a models de variables latents i pot gestionar les dades que falten. Consisteix en un pas d'estimació (pas E) i un pas de maximització (pas M), formant un procés iteratiu per millorar l'ajust del model.
- En el pas E, l'algorisme calcula les variables latents, és a dir, l'expectativa de la probabilitat logarítmica utilitzant les estimacions dels paràmetres actuals.
- En el pas M, l'algorisme determina els paràmetres que maximitzen la probabilitat logarítmica esperada obtinguda en el pas E, i els paràmetres del model corresponents s'actualitzen en funció de les variables latents estimades.

Expectació-Maximització en algorisme EM
En repetir iterativament aquests passos, l'algoritme EM busca maximitzar la probabilitat de les dades observades. S'utilitza habitualment per a tasques d'aprenentatge no supervisades, com ara l'agrupació, on es dedueixen variables latents i té aplicacions en diversos camps, com ara l'aprenentatge automàtic, la visió per ordinador i el processament del llenguatge natural.
Termes clau en l'algoritme d'expectació-maximització (EM).
Alguns dels termes clau més utilitzats en l'algorisme d'expectació-maximització (EM) són els següents:
- Variables latents: les variables latents són variables no observades en models estadístics que només es poden inferir indirectament mitjançant els seus efectes sobre variables observables. No es poden mesurar directament, però es poden detectar pel seu impacte en les variables observables. Probabilitat: És la probabilitat d'observar les dades donades donats els paràmetres del model. En l'algorisme EM, l'objectiu és trobar els paràmetres que maximitzin la probabilitat. Log-Likelihood: és el logaritme de la funció de versemblança, que mesura la bondat d'ajust entre les dades observades i el model. L'algorisme EM busca maximitzar la probabilitat logarítmica. Estimació de la màxima probabilitat (MLE): MLE és un mètode per estimar els paràmetres d'un model estadístic trobant els valors dels paràmetres que maximitzen la funció de versemblança, que mesura com de bé el model explica les dades observades. Probabilitat posterior: en el context de la inferència bayesiana, l'algorisme EM es pot estendre per estimar les estimacions màximes a posteriori (MAP), on la probabilitat posterior dels paràmetres es calcula en funció de la distribució prèvia i la funció de versemblança. Pas d'expectativa (E): el pas E de l'algorisme EM calcula el valor esperat o la probabilitat posterior de les variables latents donades les dades observades i les estimacions dels paràmetres actuals. Implica calcular les probabilitats de cada variable latent per a cada punt de dades. Pas de maximització (M): el pas M de l'algorisme EM actualitza les estimacions dels paràmetres maximitzant la probabilitat logarítmica esperada obtinguda a partir del pas E. Implica trobar els valors dels paràmetres que optimitzen la funció de versemblança, normalment mitjançant mètodes d'optimització numèrica. Convergència: la convergència fa referència a la condició en què l'algoritme EM ha arribat a una solució estable. Normalment es determina comprovant si el canvi en la probabilitat logarítmica o les estimacions dels paràmetres cau per sota d'un llindar predefinit.
Com funciona l'algoritme de maximització d'expectatives (EM):
L'essència de l'algorisme d'expectació-maximització és utilitzar les dades observades disponibles del conjunt de dades per estimar les dades que falten i després utilitzar aquestes dades per actualitzar els valors dels paràmetres. Entenem l'algorisme EM en detall.
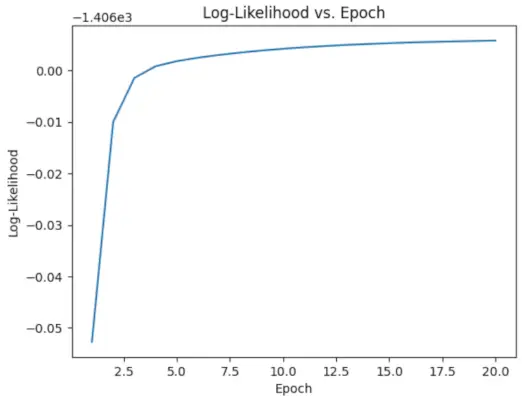
Diagrama de flux de l'algoritme EM
- Inicialització:
- Inicialment, es considera un conjunt de valors inicials dels paràmetres. Es dóna un conjunt de dades observades incompletes al sistema amb el supòsit que les dades observades provenen d'un model específic.
- Calculeu la probabilitat o responsabilitat posterior de cada variable latent ateses les dades observades i les estimacions dels paràmetres actuals.
- Estimeu els valors de dades que falten o que estan incomplets mitjançant les estimacions dels paràmetres actuals.
- Calculeu la probabilitat logarítmica de les dades observades a partir de les estimacions dels paràmetres actuals i de les dades estimades que falten.
- Actualitzeu els paràmetres del model maximitzant la probabilitat de registre de dades completa esperada obtinguda a partir del pas E.
- Normalment, això implica resoldre problemes d'optimització per trobar els valors dels paràmetres que maximitzin la probabilitat logarítmica.
- La tècnica d'optimització específica utilitzada depèn de la naturalesa del problema i del model utilitzat.
- Comproveu la convergència comparant el canvi en la probabilitat logarítmica o els valors dels paràmetres entre iteracions.
- Si el canvi està per sota d'un llindar predefinit, atureu-vos i considereu que l'algorisme ha convergit.
- En cas contrari, torneu al pas E i repetiu el procés fins a aconseguir la convergència.
Implementació pas a pas de l'algoritme d'expectació-maximització
Importa les biblioteques necessàries
Python 3
import> numpy as np> import> matplotlib.pyplot as plt> from> scipy.stats>import> norm> |
>
>
Generar un conjunt de dades amb dos components gaussians
Python 3
# Generate a dataset with two Gaussian components> mu1, sigma1>=> 2>,>1> mu2, sigma2>=> ->1>,>0.8> X1>=> np.random.normal(mu1, sigma1, size>=>200>)> X2>=> np.random.normal(mu2, sigma2, size>=>600>)> X>=> np.concatenate([X1, X2])> # Plot the density estimation using seaborn> sns.kdeplot(X)> plt.xlabel(>'X'>)> plt.ylabel(>'Density'>)> plt.title(>'Density Estimation of X'>)> plt.show()> |
>
>
Sortida :
Gràfic de densitat
pitó de cadena f
Inicialitzar paràmetres
Python 3
c matriu de cadenes de codi
# Initialize parameters> mu1_hat, sigma1_hat>=> np.mean(X1), np.std(X1)> mu2_hat, sigma2_hat>=> np.mean(X2), np.std(X2)> pi1_hat, pi2_hat>=> len>(X1)>/> len>(X),>len>(X2)>/> len>(X)> |
>
>
Realitzar algorisme EM
- Itera per al nombre especificat d'èpoques (20 en aquest cas).
- En cada època, el pas E calcula les responsabilitats (valors gamma) avaluant les densitats de probabilitat gaussianes per a cada component i ponderant-les amb les proporcions corresponents.
- El pas M actualitza els paràmetres calculant la mitjana ponderada i la desviació estàndard per a cada component
Python 3
# Perform EM algorithm for 20 epochs> num_epochs>=> 20> log_likelihoods>=> []> for> epoch>in> range>(num_epochs):> ># E-step: Compute responsibilities> >gamma1>=> pi1_hat>*> norm.pdf(X, mu1_hat, sigma1_hat)> >gamma2>=> pi2_hat>*> norm.pdf(X, mu2_hat, sigma2_hat)> >total>=> gamma1>+> gamma2> >gamma1>/>=> total> >gamma2>/>=> total> > ># M-step: Update parameters> >mu1_hat>=> np.>sum>(gamma1>*> X)>/> np.>sum>(gamma1)> >mu2_hat>=> np.>sum>(gamma2>*> X)>/> np.>sum>(gamma2)> >sigma1_hat>=> np.sqrt(np.>sum>(gamma1>*> (X>-> mu1_hat)>*>*>2>)>/> np.>sum>(gamma1))> >sigma2_hat>=> np.sqrt(np.>sum>(gamma2>*> (X>-> mu2_hat)>*>*>2>)>/> np.>sum>(gamma2))> >pi1_hat>=> np.mean(gamma1)> >pi2_hat>=> np.mean(gamma2)> > ># Compute log-likelihood> >log_likelihood>=> np.>sum>(np.log(pi1_hat>*> norm.pdf(X, mu1_hat, sigma1_hat)> >+> pi2_hat>*> norm.pdf(X, mu2_hat, sigma2_hat)))> >log_likelihoods.append(log_likelihood)> # Plot log-likelihood values over epochs> plt.plot(>range>(>1>, num_epochs>+>1>), log_likelihoods)> plt.xlabel(>'Epoch'>)> plt.ylabel(>'Log-Likelihood'>)> plt.title(>'Log-Likelihood vs. Epoch'>)> plt.show()> |
>
>
Sortida :
Època vs Log-probabilitat
Traceu la densitat estimada final
Python 3
# Plot the final estimated density> X_sorted>=> np.sort(X)> density_estimation>=> pi1_hat>*>norm.pdf(X_sorted,> >mu1_hat,> >sigma1_hat)>+> pi2_hat>*> norm.pdf(X_sorted,> >mu2_hat,> >sigma2_hat)> plt.plot(X_sorted, gaussian_kde(X_sorted)(X_sorted), color>=>'green'>, linewidth>=>2>)> plt.plot(X_sorted, density_estimation, color>=>'red'>, linewidth>=>2>)> plt.xlabel(>'X'>)> plt.ylabel(>'Density'>)> plt.title(>'Density Estimation of X'>)> plt.legend([>'Kernel Density Estimation'>,>'Mixture Density'>])> plt.show()> |
>
escàner en java
>
Sortida :
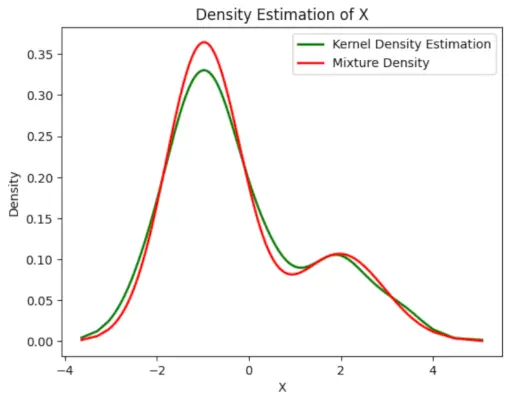
Densitat estimada
Aplicacions de la algorisme EM
- Es pot utilitzar per omplir les dades que falten en una mostra.
- Es pot utilitzar com a base de l'aprenentatge no supervisat dels clústers.
- Es pot utilitzar amb el propòsit d'estimar els paràmetres del model de Markov ocult (HMM).
- Es pot utilitzar per descobrir els valors de variables latents.
Avantatges de l'algorisme EM
- Sempre es garanteix que la probabilitat augmentarà amb cada iteració.
- El pas E i el pas M solen ser bastant fàcils per a molts problemes en termes d'implementació.
- Les solucions als passos M sovint existeixen en forma tancada.
Inconvenients de l'algorisme EM
- Té una convergència lenta.
- Fa convergència només amb els òptims locals.
- Requereix les dues probabilitats, cap endavant i cap enrere (l'optimització numèrica només requereix probabilitat cap endavant).