Al món real, no totes les dades amb les quals treballem tenen una variable objectiu. Aquest tipus de dades no es poden analitzar mitjançant algorismes d'aprenentatge supervisat. Necessitem l'ajuda d'algorismes no supervisats. Un dels tipus d'anàlisi més populars sota aprenentatge no supervisat és segmentació de clients per a anuncis orientats, o en imatges mèdiques per trobar àrees infectades desconegudes o noves i molts més casos d'ús que parlarem més en aquest article.
Taula de contingut
- Què és el Clustering?
- Tipus de clúster
- Usos de l'agrupació
- Tipus d'algorismes d'agrupació
- Aplicacions del Clustering en diferents camps:
- Preguntes freqüents (FAQ) sobre clúster
Què és el Clustering?
La tasca d'agrupar els punts de dades en funció de la seva similitud entre si s'anomena clúster o anàlisi de clúster. Aquest mètode es defineix sota la branca de Aprenentatge no supervisat , que té com a objectiu obtenir informació de punts de dades sense etiquetar, és a dir, a diferència aprenentatge supervisat no tenim una variable objectiu.
El clúster té com a objectiu formar grups de punts de dades homogenis a partir d'un conjunt de dades heterogeni. Avalua la similitud en funció d'una mètrica com ara la distància euclidiana, la similitud del cosinus, la distància de Manhattan, etc. i després agrupa els punts amb la puntuació de semblança més alta.
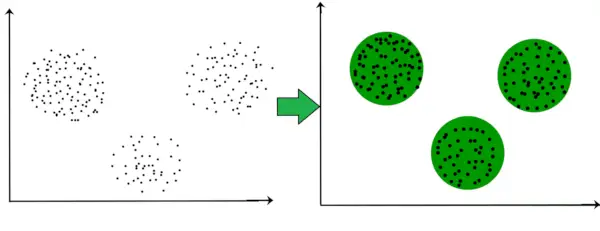
Per exemple, al gràfic que es mostra a continuació, podem veure clarament que hi ha 3 cúmuls circulars que es formen en funció de la distància.
pandes i numpy
Ara no cal que els cúmuls formats tinguin forma circular. La forma dels clústers pot ser arbitrària. Hi ha molts algorismes que funcionen bé amb la detecció de clústers de forma arbitraria.
Per exemple, al gràfic següent podem veure que els cúmuls formats no tenen forma circular.
mapa rendir

Tipus de clúster
En termes generals, hi ha 2 tipus d'agrupaments que es poden realitzar per agrupar punts de dades similars:
- Clúster dur: En aquest tipus de clúster, cada punt de dades pertany completament o no a un clúster. Per exemple, suposem que hi ha 4 punts de dades i els hem d'agrupar en 2 clústers. Per tant, cada punt de dades pertany al clúster 1 o al clúster 2.
| Punts de dades | Clústers |
|---|---|
| A | C1 |
| B | C2 |
| C | C2 |
| D | C1 |
- Agrupació suau: En aquest tipus de clúster, en lloc d'assignar cada punt de dades a un clúster separat, s'avalua una probabilitat o probabilitat que aquest punt sigui aquest clúster. Per exemple, suposem que hi ha 4 punts de dades i els hem d'agrupar en 2 clústers. Per tant, avaluarem una probabilitat d'un punt de dades pertanyent als dos clústers. Aquesta probabilitat es calcula per a tots els punts de dades.
| Punts de dades | Probabilitat de C1 | Probabilitat de C2 |
| A | 0.91 | 0,09 |
| B | 0.3 | 0.7 |
| C | 0.17 | 0.83 |
| D | 1 | 0 |
Usos de l'agrupació
Ara, abans de començar amb els tipus d'algorismes d'agrupació, passarem pels casos d'ús dels algorismes de clúster. Els algorismes de clúster s'utilitzen principalment per a:
- La segmentació del mercat – Les empreses utilitzen agrupacions per agrupar els seus clients i utilitzen anuncis orientats per atraure més audiència.
- Anàlisi de xarxes socials – Els llocs de xarxes socials utilitzen les vostres dades per entendre el vostre comportament de navegació i oferir-vos recomanacions d'amics o de contingut orientades.
- Imatge mèdica: els metges utilitzen l'agrupació per esbrinar àrees malaltes en imatges de diagnòstic com ara els raigs X.
- Detecció d'anomalies – Per trobar valors atípics en un flux de dades en temps real o per preveure transaccions fraudulentes, podem utilitzar l'agrupació per identificar-los.
- Simplifica el treball amb grans conjunts de dades: a cada clúster se li dóna un identificador de clúster un cop finalitzada la agrupació. Ara, podeu reduir tot el conjunt de funcions d'un conjunt de funcions al seu identificador de clúster. La agrupació en clúster és eficaç quan pot representar un cas complicat amb un identificador de clúster senzill. Utilitzant el mateix principi, agrupar dades pot simplificar conjunts de dades complexos.
Hi ha molts més casos d'ús per a l'agrupació, però hi ha alguns dels casos d'ús principals i habituals de l'agrupació. A partir d'ara, parlarem dels algorismes de agrupació que us ajudaran a realitzar les tasques anteriors.
Tipus d'algorismes d'agrupació
A nivell superficial, l'agrupació ajuda en l'anàlisi de dades no estructurades. La gràfica, la distància més curta i la densitat dels punts de dades són alguns dels elements que influeixen en la formació de clúster. L'agrupament és el procés de determinar com estan relacionats els objectes basant-se en una mètrica anomenada mesura de semblança. Les mètriques de semblança són més fàcils de localitzar en conjunts més petits de funcions. Es fa més difícil crear mesures de similitud a mesura que augmenta el nombre de funcions. Depenent del tipus d'algorisme d'agrupació que s'utilitza en la mineria de dades, s'utilitzen diverses tècniques per agrupar les dades dels conjunts de dades. En aquesta part es descriuen les tècniques de clustering. Hi ha diversos tipus d'algorismes d'agrupació:
- Clúster basat en centroides (mètodes de partició)
- Agrupació basada en la densitat (mètodes basats en models)
- Clúster basat en connectivitat (agrupació jeràrquica)
- Clúster basat en la distribució
Repassarem breument cadascun d'aquests tipus.
1. Els mètodes de partició són els algorismes de agrupació més senzills. Agrupen els punts de dades en funció de la seva proximitat. En general, la mesura de semblança escollida per a aquests algorismes són la distància euclidiana, la distància de Manhattan o la distància de Minkowski. Els conjunts de dades es separen en un nombre predeterminat de clústers, i cada clúster té referència a un vector de valors. En comparació amb el valor vectorial, la variable de dades d'entrada no mostra cap diferència i s'uneix al clúster.
El principal inconvenient d'aquests algorismes és el requisit d'establir el nombre de clústers, k, de manera intuïtiva o científica (utilitzant el mètode Elbow) abans que qualsevol sistema d'aprenentatge automàtic de clúster comenci a assignar els punts de dades. Malgrat això, segueix sent el tipus de clustering més popular. K-significa i K-medoides clustering són alguns exemples d'aquest tipus de clustering.
algorisme per a bfs
2. Agrupació basada en la densitat (mètodes basats en models)
La agrupació basada en la densitat, un mètode basat en models, troba grups basats en la densitat de punts de dades. Contràriament a la agrupació basada en el centroide, que requereix que el nombre de clústers estigui predefinit i sigui sensible a la inicialització, la agrupació basada en la densitat determina el nombre de clústers automàticament i és menys susceptible a les posicions inicials. Són excel·lents per manejar clústers de diferents mides i formes, cosa que els fa ideals per a conjunts de dades amb clústers de forma irregular o superposats. Aquests mètodes gestionen regions de dades tant denses com disperses centrant-se en la densitat local i poden distingir clústers amb una varietat de morfologies.
En canvi, l'agrupació basada en el centroide, com els k-means, té problemes per trobar clústers de forma arbitraria. A causa del seu nombre preestablert de requisits de clúster i de la seva extrema sensibilitat al posicionament inicial dels centroides, els resultats poden variar. A més, la tendència dels enfocaments basats en el centroide per produir cúmuls esfèrics o convexos restringeix la seva capacitat per manejar cúmuls complicats o de forma irregular. En conclusió, la agrupació basada en la densitat supera els inconvenients de les tècniques basades en el centroide escollint de forma autònoma mides de clúster, sent resistent a la inicialització i captura amb èxit clústers de diverses mides i formes. L'algorisme de agrupació basat en densitat més popular és DBSCAN .
3. Clúster basat en connectivitat (agrupació jeràrquica)
Un mètode per reunir punts de dades relacionats en clústers jeràrquics s'anomena agrupació jeràrquica. Cada punt de dades es té en compte inicialment com un clúster separat, que es combina posteriorment amb els clústers que són més semblants per formar un clúster gran que conté tots els punts de dades.
Penseu en com podeu organitzar una col·lecció d'articles en funció de la seva semblança. Cada objecte comença com el seu propi clúster a la base de l'arbre quan s'utilitza l'agrupació jeràrquica, que crea un dendrograma, una estructura semblant a un arbre. Els aparellaments de clústers més propers es combinen en grups més grans després que l'algoritme examini la semblança que tenen els objectes entre si. Quan cada objecte es troba en un clúster a la part superior de l'arbre, el procés de fusió ha acabat. Explorar diversos nivells de granularitat és una de les coses divertides de la agrupació jeràrquica. Per obtenir un nombre determinat de clústers, podeu seleccionar tallar el dendrograma a una alçada determinada. Com més semblants hi ha dos objectes dins d'un clúster, més a prop estan. És comparable a classificar els elements segons els seus arbres genealògics, on els parents més propers s'agrupen i les branques més amples signifiquen connexions més generals. Hi ha 2 enfocaments per a la agrupació jeràrquica:
- Agrupació divisoria : Segueix un enfocament de dalt a baix, aquí considerem que tots els punts de dades formen part d'un gran clúster i després aquest clúster es divideix en grups més petits.
- Clúster aglomeratiu : Segueix un enfocament de baix a dalt, aquí considerem que tots els punts de dades formen part de clústers individuals i, a continuació, aquests clústers es combinen per formar un gran clúster amb tots els punts de dades.
4. Clúster basat en la distribució
Mitjançant l'agrupament basat en la distribució, els punts de dades es generen i s'organitzen segons la seva propensió a caure en la mateixa distribució de probabilitat (com ara un gaussià, un binomi o una altra) dins de les dades. Els elements de dades s'agrupen mitjançant una distribució basada en probabilitats que es basa en distribucions estadístiques. S'inclouen objectes de dades que tenen una probabilitat més alta d'estar al clúster. És menys probable que un punt de dades s'inclogui en un clúster com més lluny estigui del punt central del clúster, que existeix a cada clúster.
Un inconvenient notable dels enfocaments basats en la densitat i els límits és la necessitat d'especificar els clústers a priori per a alguns algorismes, i principalment la definició de la forma del clúster per a la majoria d'algorismes. Hi ha d'haver seleccionat almenys una sintonia o hiper-paràmetre i, tot i que fer-ho hauria de ser senzill, equivocar-se podria tenir repercussions imprevistes. La agrupació basada en la distribució té un avantatge definitiu sobre els enfocaments de clúster basats en la proximitat i el centroide en termes de flexibilitat, precisió i estructura de clúster. La qüestió clau és que, per evitar sobreajustament , molts mètodes d'agrupació només funcionen amb dades simulades o fabricades, o quan la majoria dels punts de dades pertanyen sens dubte a una distribució predeterminada. L'algoritme de clustering basat en la distribució més popular és Model gaussià de mescles .
Aplicacions del Clustering en diferents camps:
- Màrqueting: Es pot utilitzar per caracteritzar i descobrir segments de clients amb finalitats de màrqueting.
- Biologia: Es pot utilitzar per a la classificació entre diferents espècies de plantes i animals.
- Biblioteques: S'utilitza per agrupar diferents llibres sobre la base de temes i informació.
- Assegurança: S'utilitza per reconèixer els clients, les seves polítiques i identificar els fraus.
- Urbanisme: S'utilitza per fer grups de cases i per estudiar els seus valors en funció de la seva ubicació geogràfica i altres factors presents.
- Estudis de terratrèmols: Aprenent les zones afectades pel terratrèmol podem determinar les zones perilloses.
- Processament d'imatge : l'agrupació es pot utilitzar per agrupar imatges similars, classificar imatges segons el contingut i identificar patrons a les dades d'imatge.
- Genètica: L'agrupament s'utilitza per agrupar gens que tenen patrons d'expressió similars i identificar xarxes de gens que treballen conjuntament en processos biològics.
- Finances: L'agrupació s'utilitza per identificar segments de mercat basats en el comportament dels clients, identificar patrons a les dades del mercat de valors i analitzar el risc de les carteres d'inversió.
- Servei d'atenció al client: L'agrupament s'utilitza per agrupar les consultes i queixes dels clients en categories, identificar problemes comuns i desenvolupar solucions específiques.
- Fabricació : El clúster s'utilitza per agrupar productes similars, optimitzar els processos de producció i identificar defectes en els processos de fabricació.
- Diagnòstic mèdic: La agrupació s'utilitza per agrupar pacients amb símptomes o malalties similars, la qual cosa ajuda a fer diagnòstics precisos i identificar tractaments efectius.
- Detecció de frau: La agrupació s'utilitza per identificar patrons sospitosos o anomalies en les transaccions financeres, que poden ajudar a detectar fraus o altres delictes financers.
- Anàlisi del trànsit: La agrupació s'utilitza per agrupar patrons similars de dades de trànsit, com ara les hores punta, les rutes i les velocitats, que poden ajudar a millorar la planificació i la infraestructura del transport.
- Anàlisi de xarxes socials: L'agrupament s'utilitza per identificar comunitats o grups dins de les xarxes socials, cosa que pot ajudar a entendre el comportament, la influència i les tendències socials.
- Seguretat cibernètica: L'agrupament s'utilitza per agrupar patrons similars de trànsit de xarxa o comportament del sistema, que poden ajudar a detectar i prevenir ciberatacs.
- Anàlisi climàtica: La agrupació s'utilitza per agrupar patrons similars de dades climàtiques, com ara la temperatura, la precipitació i el vent, que poden ajudar a entendre el canvi climàtic i el seu impacte en el medi ambient.
- Anàlisi esportiva: L'agrupament s'utilitza per agrupar patrons similars de dades de rendiment de jugadors o equips, que poden ajudar a analitzar els punts forts i febles dels jugadors o equips i prendre decisions estratègiques.
- Anàlisi delictiva: L'agrupació s'utilitza per agrupar patrons similars de dades de delinqüència, com ara la ubicació, l'hora i el tipus, que poden ajudar a identificar els punts delictius, predir tendències futures de delinqüència i millorar les estratègies de prevenció de la delinqüència.
Conclusió
En aquest article hem parlat del clúster, els seus tipus i les seves aplicacions al món real. Hi ha molt més per cobrir en l'aprenentatge no supervisat i l'anàlisi de clústers és només el primer pas. Aquest article us pot ajudar a començar amb els algorismes de clúster i ajudar-vos a obtenir un projecte nou que es pugui afegir a la vostra cartera.
Preguntes freqüents (FAQ) sobre clúster
P. Quin és el millor mètode d'agrupació?
Els 10 principals algorismes de clustering són:
significat de dhl
- K significa agrupació
- Clúster jeràrquic
- DBSCAN (agrupació espacial d'aplicacions amb soroll basada en densitat)
- Models de mescles gaussianes (GMM)
- Clúster aglomeratiu
- Clúster espectral
- Agrupació de canvi mitjà
- Propagació d'afinitat
- ÒPTICA (Punts d'ordenació per identificar l'estructura de clúster)
- Birch (reducció iterativa equilibrada i agrupació mitjançant jerarquies)
P. Quina diferència hi ha entre agrupació i classificació?
La diferència principal entre l'agrupació i la classificació és que, la classificació és un algorisme d'aprenentatge supervisat i la agrupació és un algorisme d'aprenentatge no supervisat. És a dir, apliquem l'agrupació a aquells conjunts de dades que no tenen una variable objectiu.
P. Quins són els avantatges de l'anàlisi de clúster?
Les dades es poden organitzar en grups significatius mitjançant la forta eina analítica de l'anàlisi de clústers. Podeu utilitzar-lo per identificar segments, trobar patrons ocults i millorar les decisions.
P. Quin és el mètode d'agrupació més ràpid?
La agrupació K-means sovint es considera el mètode de agrupació més ràpid a causa de la seva senzillesa i eficiència computacional. Assigna de manera iterativa punts de dades al centroide del clúster més proper, el que el fa adequat per a grans conjunts de dades amb una dimensionalitat baixa i un nombre moderat de clústers.
P. Quines són les limitacions de l'agrupació?
Les limitacions de l'agrupació inclouen la sensibilitat a les condicions inicials, la dependència de l'elecció dels paràmetres, la dificultat per determinar el nombre òptim de clústers i els reptes amb el maneig de dades d'alta dimensió o sorollosos.
P. De què depèn la qualitat del resultat del clustering?
La qualitat dels resultats de la agrupació depèn de factors com l'elecció de l'algorisme, la mètrica de distància, el nombre de clústers, el mètode d'inicialització, les tècniques de preprocessament de dades, les mètriques d'avaluació de clúster i el coneixement del domini. Aquests elements influeixen col·lectivament en l'eficàcia i la precisió del resultat de l'agrupació.