Pandes dataframe.corr() s'utilitza per trobar la correlació per parelles de totes les columnes del Pandas Dataframe a Python. Cap NaN els valors s'exclouen automàticament. Per ignorar qualsevol valor no numèric, utilitzeu el paràmetre numeric_only = True. En aquest article, aprendrem sobre el mètode DataFrame.corr() a Python .
Sintaxi del mètode Pandas DataFrame corr().
Sintaxi: DataFrame.corr(self, method='pearson', min_periods=1, numeric_only = Fals)
Paràmetres:
- mètode:
- Pearson: coeficient de correlació estàndard
- kendall: coeficient de correlació Kendall Tau
- spearman: correlació de rang de Spearman
- períodes_min: Nombre mínim d'observacions necessàries per parell de columnes per tenir un resultat vàlid. Actualment només disponible per a la correlació Pearson i Spearman
- numeric_only : si només s'han d'operar els valors numèrics o no. S'estableix com a Fals per defecte.
Devolucions: count :y : DataFrame
Correlacions de dades Pandas Mètode corr().
Una bona correlació depèn de l'ús, però és segur dir que teniu almenys 0,6 (o -0,6) per anomenar-la una bona correlació. Un exemple senzill per mostrar com funciona la correlació Python .
Python 3
import> pandas as pd> df>=> {> >'Array_1'>: [>30>,>70>,>100>],> >'Array_2'>: [>65.1>,>49.50>,>30.7>]> }> data>=> pd.DataFrame(df)> print>(data.corr())> |
>
>
Sortida
Array_1 Array_2 Array_1 1.000000 -0.990773 Array_2 -0.990773 1.000000>
Creació d'un marc de dades de mostra
Impressió de les 10 primeres files del Dataframe.
Nota: La correlació d'una variable amb ella mateixa és 1. Per obtenir un enllaç al fitxer CSV utilitzat al codi, feu clic aquí
Python 3
números per a l'alfabet
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # Printing the first 10 rows of the data frame for visualization> df[:>10>]> |
>
>
Sortida

Exemples de mètodes Python Pandas DataFrame corr().
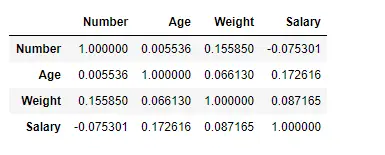
Trobeu la correlació entre les columnes utilitzant el mètode de Pearson
Aquí, estem utilitzant la funció corr() per trobar la correlació entre les columnes del Dataframe mitjançant el mètode 'Pearson'. Només tenim quatre columnes numèriques al Dataframe. El Dataframe de sortida es pot interpretar com per a qualsevol cel·la, la correlació de la variable de fila amb la variable de columna és el valor de la cel·la. Com s'ha esmentat anteriorment, la correlació d'una variable amb ella mateixa és 1. Per aquest motiu, tots els valors diagonals són 1,00.
Python 3
# To find the correlation among> # the columns using pearson method> df.corr(method>=>'pearson'>)> |
>
>
Sortida
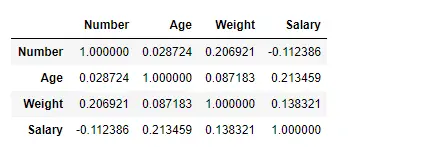
Trobeu la correlació entre les columnes utilitzant el mètode Kendall
Utilitzeu la funció Pandas df.corr() per trobar la correlació entre les columnes del Dataframe mitjançant el mètode 'kendall'. El Dataframe de sortida es pot interpretar com per a qualsevol cel·la, la correlació de la variable de fila amb la variable de columna és el valor de la cel·la. Com s'ha esmentat anteriorment, la correlació d'una variable amb ella mateixa és 1. Per aquest motiu, tots els valors diagonals són 1,00.
Python 3
matriu dinàmica en java
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # To find the correlation among> # the columns using kendall method> df.corr(method>=>'kendall'>)> |
>
>
Sortida