L'ordre uniq de Linux s'utilitza per eliminar totes les línies repetides d'un fitxer. A més, es pot utilitzar per mostrar un recompte de qualsevol paraula, només línies repetides, ignorar caràcters i comparar camps específics. És una de les ordres més utilitzades a el Linux sistema. S'utilitza sovint amb el comanda ordenar perquè compara personatges adjacents. Descarta totes les línies idèntiques i escriu la sortida.
Sintaxi:
uniq [OPTION]... [INPUT [OUTPUT]]
Opcions:
Algunes opcions útils de la línia d'ordres de l'ordre uniq són les següents:
-c, --count: prefixa les línies pel nombre d'ocurrències.
-d, --repeteix: s'utilitza per imprimir línies duplicades, una per a cada grup.
-D: S'utilitza per imprimir totes les línies duplicades.
--tot-repetit[=METODE]: És força semblant a l'opció '-D', la diferència entre ambdues opcions és que permet la separació de grups amb una línia buida.
nbsp
-f, --skip-fields=N: S'utilitza per evitar la comparació dels primers N camps.
quantes setmanes hi ha en un mes
--grup[=METODE]: S'utilitza per mostrar tots els elements i separa els grups amb una línia buida.
-i, --ignore-case: S'utilitza per ignorar les diferències mentre es comparen.
-s, --skip-chars=N: S'utilitza per evitar la comparació dels primers N caràcters.
-u, --únic: s'utilitza per imprimir línies úniques.
-z, --zero-terminat: S'utilitza perquè el delimitador de línia és NUL i no el mode de nova línia.
-w, --check-chars=N: S'utilitza per comparar no més de N caràcters en línies.
--ajuda: S'utilitza per mostrar la documentació d'ajuda.
--versió: S'utilitza per mostrar la informació de la versió.
Exemples de comandament uniq
Vegem els següents exemples de l'ordre uniq:
- Elimina les línies repetides
- comptar el nombre d'ocurrències d'una paraula
- Mostra les línies repetides
- Mostra les línies úniques
- Ignora els personatges en comparació
- Ignora els camps en comparació
Elimina les línies repetides
Per eliminar línies repetides d'un fitxer, executeu l'ordre bàsic uniq de la següent manera:
bucles java
sort dupli.txt | uniq
L'ordre anterior eliminarà les línies duplicades del fitxer 'dupli.txt'. Considereu la sortida següent:
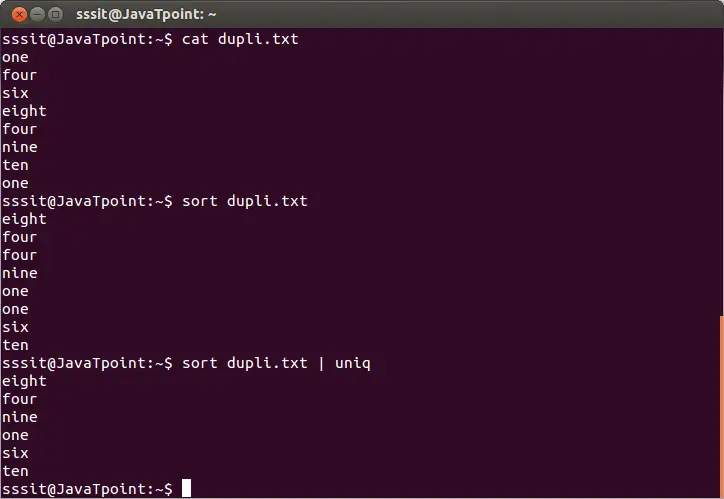
A partir de la sortida anterior, s'ignoren les paraules que es repeteixen.
Comptar el nombre d'ocurrències d'una paraula
Podem comptar el nombre d'ocurrències d'una paraula utilitzant l'ordre uniq. L'opció '-c' s'utilitza per comptar la paraula. Executeu-ho de la següent manera:
sort dupli.txt | uniq -c
L'ordre anterior comptarà les paraules que vénen a 'dupli.txt'. Considereu la sortida següent:

A la sortida anterior, l'ordre 'sort dupli.txt | uniq -c' compta el nombre de vegades que es repeteix una paraula.
Mostra les línies repetides
L'opció '-d' s'utilitza per mostrar només les línies repetides. Només mostrarà les línies que estaran més d'una vegada en un fitxer i escriurà la sortida a la sortida estàndard. Considereu l'ordre següent:
Rajesh Khanna
sort dupli.txt | uniq -d
L'ordre anterior mostrarà només les línies repetides. Considereu la sortida següent:

Mostra les línies úniques
L'opció '-u' s'utilitza per mostrar només les línies úniques (que no es repeteixen). Només mostrarà les línies que es produeixen només una vegada i escriurà el resultat a la sortida estàndard. Considereu l'ordre següent:
sort dupli.txt | uniq -u
L'ordre anterior mostrarà només les línies úniques del fitxer 'dupli.txt'. Considereu la sortida següent:
configuració del camí de Python

Ignora els personatges en comparació
L'opció '-s' s'utilitza per ignorar els caràcters en comparació. Ignorarà el nombre especificat de caràcters i mostrarà el resultat a la sortida estàndard. Considereu l'ordre següent:
sort dupli.txt | uniq -s 2
L'ordre anterior ignorarà els dos primers caràcters en comparació del fitxer 'dupli.txt'. Considereu la sortida següent:

Ignora els camps en comparació
L'opció '-f' s'utilitza per ignorar els camps. Considereu l'ordre següent:
uniq -f 2 dupli2.txt
L'ordre anterior no compararà els dos primers camps del fitxer 'dupli2.txt'. Considereu la sortida següent:

A partir de la sortida anterior, els dos primers camps s'ometen i la resta de tots els camps es comparen des del fitxer 'dupli2.txt'.