Els mapes hash són estructures de dades indexades. Un mapa hash fa ús de a funció hash per calcular un índex amb una clau en una matriu de cubs o ranures. El seu valor s'assigna al cub amb l'índex corresponent. La clau és única i immutable. Penseu en un mapa hash com un armari amb calaixos amb etiquetes per a les coses emmagatzemades. Per exemple, emmagatzemar informació de l'usuari: considereu el correu electrònic com a clau i podem assignar els valors corresponents a aquest usuari, com ara el nom, el cognom, etc. a un cub.
La funció hash és el nucli de la implementació d'un mapa hash. Agafa la clau i la tradueix a l'índex d'un cub a la llista de cubs. El hashing ideal hauria de produir un índex diferent per a cada clau. Tanmateix, es poden produir col·lisions. Quan el resum proporciona un índex existent, simplement podem utilitzar un cub per a diversos valors afegint una llista o repetint.
A Python, els diccionaris són exemples de mapes hash. Veurem la implementació del mapa hash des de zero per aprendre a crear i personalitzar aquestes estructures de dades per optimitzar la cerca.
git superi
El disseny del mapa hash inclourà les funcions següents:
- set_val(clau, valor): Insereix una parella clau-valor al mapa hash. Si el valor ja existeix al mapa hash, actualitzeu-lo.
- get_val(clau): Retorna el valor al qual s'ha assignat la clau especificada, o No s'ha trobat cap registre si aquest mapa no conté cap assignació per a la clau.
- delete_val(clau): Elimina el mapeig de la clau específica si el mapa hash conté el mapeig de la clau.
A continuació es mostra la implementació.
Python 3
exemples d'arbres binaris
class> HashTable:> ># Create empty bucket list of given size> >def> __init__(>self>, size):> >self>.size>=> size> >self>.hash_table>=> self>.create_buckets()> >def> create_buckets(>self>):> >return> [[]>for> _>in> range>(>self>.size)]> ># Insert values into hash map> >def> set_val(>self>, key, val):> > ># Get the index from the key> ># using hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key to be inserted> >if> record_key>=>=> key:> >found_key>=> True> >break> ># If the bucket has same key as the key to be inserted,> ># Update the key value> ># Otherwise append the new key-value pair to the bucket> >if> found_key:> >bucket[index]>=> (key, val)> >else>:> >bucket.append((key, val))> ># Return searched value with specific key> >def> get_val(>self>, key):> > ># Get the index from the key using> ># hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key being searched> >if> record_key>=>=> key:> >found_key>=> True> >break> ># If the bucket has same key as the key being searched,> ># Return the value found> ># Otherwise indicate there was no record found> >if> found_key:> >return> record_val> >else>:> >return> 'No record found'> ># Remove a value with specific key> >def> delete_val(>self>, key):> > ># Get the index from the key using> ># hash function> >hashed_key>=> hash>(key)>%> self>.size> > ># Get the bucket corresponding to index> >bucket>=> self>.hash_table[hashed_key]> >found_key>=> False> >for> index, record>in> enumerate>(bucket):> >record_key, record_val>=> record> > ># check if the bucket has same key as> ># the key to be deleted> >if> record_key>=>=> key:> >found_key>=> True> >break> >if> found_key:> >bucket.pop(index)> >return> ># To print the items of hash map> >def> __str__(>self>):> >return> ''.join(>str>(item)>for> item>in> self>.hash_table)> hash_table>=> HashTable(>50>)> # insert some values> hash_table.set_val(>'[email protected]'>,>'some value'>)> print>(hash_table)> print>()> hash_table.set_val(>'[email protected]'>,>'some other value'>)> print>(hash_table)> print>()> # search/access a record with key> print>(hash_table.get_val(>'[email protected]'>))> print>()> # delete or remove a value> hash_table.delete_val(>'[email protected]'>)> print>(hash_table)> |
>
>
Sortida:
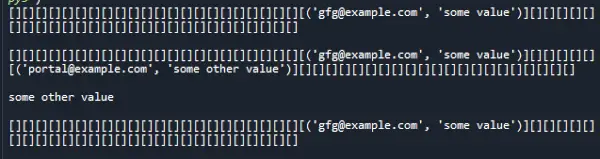
Complexitat temporal:
L'accés a l'índex de memòria triga un temps constant i el hash triga un temps constant. Per tant, la complexitat de cerca d'un mapa hash també és un temps constant, és a dir, O(1).
Avantatges de HashMaps
● Accés ràpid a la memòria aleatòria mitjançant funcions hash
● Pot utilitzar valors negatius i no integrals per accedir als valors.
● Les claus es poden emmagatzemar en ordre ordenat, per tant, es poden iterar pels mapes fàcilment.
Desavantatges de HashMaps
hola món java
● Les col·lisions poden causar grans penalitzacions i poden augmentar la complexitat del temps a lineal.
● Quan el nombre de tecles és gran, una única funció hash sovint provoca col·lisions.
Aplicacions de HashMaps
● Aquests tenen aplicacions en implementacions de la memòria cau en què les ubicacions de memòria s'assignen a conjunts petits.
● S'utilitzen per indexar tuples en sistemes de gestió de bases de dades.
● També s'utilitzen en algorismes com la concordança de patrons de Rabin Karp