Un aspecte important de Aprenentatge automàtic és l'avaluació del model. Heu de tenir algun mecanisme per avaluar el vostre model. Aquí és on entren en escena aquestes mètriques de rendiment que ens donen una idea de com de bo és un model. Si coneixeu alguns dels conceptes bàsics de Aprenentatge automàtic llavors haureu d'haver trobat algunes d'aquestes mètriques, com ara la precisió, la precisió, la memòria, l'auc-roc, etc., que s'utilitzen generalment per a tasques de classificació. En aquest article, explorarem en profunditat una d'aquestes mètriques, que és la corba AUC-ROC.
Taula de contingut
- Què és la corba AUC-ROC?
- Termes clau utilitzats a la corba AUC i ROC
- Relació entre sensibilitat, especificitat, FPR i llindar.
- Com funciona AUC-ROC?
- Quan hem d'utilitzar la mètrica d'avaluació AUC-ROC?
- Especulant el rendiment del model
- Comprensió de la corba AUC-ROC
- Implementació mitjançant dos models diferents
- Com utilitzar ROC-AUC per a un model multiclasse?
- Preguntes freqüents sobre la corba AUC ROC en aprenentatge automàtic
Què és la corba AUC-ROC?
La corba AUC-ROC, o corba de l'àrea sota la característica de funcionament del receptor, és una representació gràfica del rendiment d'un model de classificació binari a diversos llindars de classificació. S'utilitza habitualment en l'aprenentatge automàtic per avaluar la capacitat d'un model per distingir entre dues classes, normalment la classe positiva (per exemple, presència d'una malaltia) i la classe negativa (per exemple, absència d'una malaltia).
Primer entenem el significat dels dos termes ROC i AUC .
- ROC : Característiques de funcionament del receptor
- AUC : Àrea sota corba
Corba de les característiques de funcionament del receptor (ROC).
ROC significa Receiver Operating Characteristics, i la corba ROC és la representació gràfica de l'efectivitat del model de classificació binària. Representa la taxa de veritable positiu (TPR) versus la taxa de fals positiu (FPR) en diferents llindars de classificació.
Àrea sota corba (AUC) Corba:
AUC significa l'àrea sota la corba, i la corba AUC representa l'àrea sota la corba ROC. Mesura el rendiment global del model de classificació binària. Com que tant el TPR com el FPR oscil·len entre 0 i 1, l'àrea sempre estarà entre 0 i 1, i un valor més gran d'AUC denota un millor rendiment del model. El nostre objectiu principal és maximitzar aquesta àrea per tenir el TPR més alt i el FPR més baix en el llindar donat. L'AUC mesura la probabilitat que el model assigni a una instància positiva escollida aleatòriament una probabilitat prevista més alta en comparació amb una instància negativa escollida aleatòriament.
Representa el probabilitat amb la qual el nostre model pot distingir entre les dues classes presents al nostre objectiu.
Mètrica d'avaluació de la classificació ROC-AUC
Termes clau utilitzats a la corba AUC i ROC
1. TPR i FPR
Aquesta és la definició més comuna que hauríeu trobat quan haguéssiu Google AUC-ROC. Bàsicament, la corba ROC és un gràfic que mostra el rendiment d'un model de classificació en tots els llindars possibles (el llindar és un valor particular més enllà del qual dius que un punt pertany a una classe concreta). La corba es representa entre dos paràmetres
- TPR - Taxa Veritable Positiva
- FPR – Taxa de fals positius
Abans d'entendre-ho, TPR i FPR ens permeten mirar ràpidament matriu de confusió .
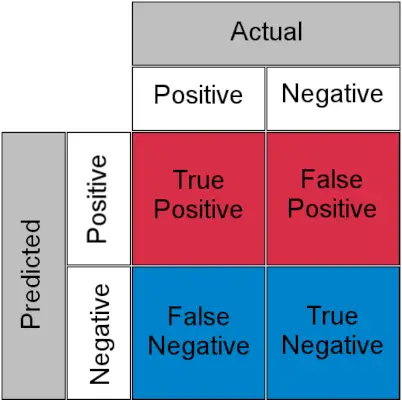
Matriu de confusió per a una tasca de classificació
- Veritable positiu : Positiu real i predit com a positiu
- Veritable negatiu : negatiu real i predit com a negatiu
- Fals positiu (error de tipus I) : negatiu real però previst com a positiu
- Fals negatiu (error de tipus II) : positiu real però previst com a negatiu
En termes senzills, podeu anomenar fals positiu a falsa alarma i fals negatiu a senyoreta . Ara mirem què són TPR i FPR.
2. Sensibilitat / Índex Veritable Positiu / Record
Bàsicament, TPR/Record/Sensitivity és la proporció d'exemples positius que s'identifiquen correctament. Representa la capacitat del model per identificar correctament instàncies positives i es calcula de la següent manera:

La sensibilitat/record/TPR mesura la proporció d'instàncies positives reals que el model identifica correctament com a positives.
3. Taxa de fals positius
FPR és la proporció d'exemples negatius que estan mal classificats.

4. Especificitat
L'especificitat mesura la proporció d'instàncies negatives reals que el model identifica correctament com a negatives. Representa la capacitat del model per identificar correctament les instàncies negatives

I com s'ha dit anteriorment, ROC no és més que la trama entre TPR i FPR en tots els llindars possibles i AUC és tota l'àrea sota aquesta corba ROC.
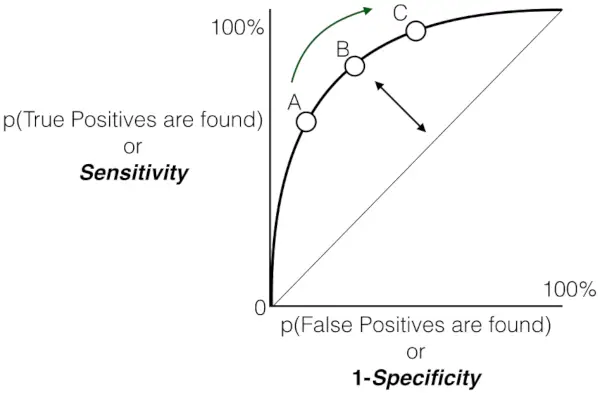
Gràfic de la sensibilitat versus la taxa de fals positius
Relació entre sensibilitat, especificitat, FPR i llindar .
Sensibilitat i especificitat:
- Relació inversa: sensibilitat i especificitat tenen una relació inversa. Quan un augmenta, l'altre tendeix a disminuir. Això reflecteix el compromís inherent entre les taxes positives i negatives.
- Afinació mitjançant Threshold: Ajustant el valor llindar, podem controlar l'equilibri entre sensibilitat i especificitat. Els llindars més baixos condueixen a una sensibilitat més alta (més positius veritables) a costa de l'especificitat (més falsos positius). Per contra, augmentar el llindar augmenta l'especificitat (menys falsos positius) però sacrifica la sensibilitat (més falsos negatius).
Llindar i taxa de falsos positius (FPR):
- Connexió FPR i especificitat: La taxa de fals positius (FPR) és simplement el complement de l'especificitat (FPR = 1 - especificitat). Això significa la relació directa entre ells: una major especificitat es tradueix en una FPR més baixa, i viceversa.
- Canvis de FPR amb TPR: De la mateixa manera, com heu observat, la taxa veritable positiva (TPR) i la FPR també estan vinculades. Un augment de la TPR (més positius veritables) generalment condueix a un augment de la FPR (més falsos positius). Per contra, una caiguda de la TPR (menys positius veritables) provoca una disminució de la FPR (menys falsos positius)
Com funciona AUC-ROC?
Hem observat la interpretació geomètrica, però suposo que encara no n'hi ha prou per desenvolupar la intuïció darrere del que realment significa 0,75 AUC, ara mirem AUC-ROC des d'un punt de vista probabilístic. Parlem primer del que fa l'AUC i més tard construirem la nostra comprensió sobre això
AUC mesura fins a quin punt un model és capaç de distingir classes.
Un AUC de 0,75 en realitat significaria que suposem que prenem dos punts de dades que pertanyen a classes separades, llavors hi ha un 75% de possibilitats que el model pugui separar-los o ordenar-los correctament, és a dir, el punt positiu té una probabilitat de predicció més alta que el negatiu. classe. (suposant una probabilitat de predicció més alta significa que el punt idealment pertanyi a la classe positiva). Aquí teniu un petit exemple per deixar les coses més clares.
Índex | Classe | Probabilitat |
|---|---|---|
P1 | 1 | 0.95 |
P2 | 1 | 0.90 |
P3 | 0 | 0.85 |
P4 | 0 | 0.81 |
P5 | 1 | 0.78 |
P6 | 0 | 0.70 |
Aquí tenim 6 punts on P1, P2 i P5 pertanyen a la classe 1 i P3, P4 i P6 pertanyen a la classe 0 i ens corresponen les probabilitats previstes a la columna Probabilitat, com hem dit si prenem dos punts que pertanyen a separats. classes, aleshores quina és la probabilitat que el rang del model les ordeni correctament.
Prenem totes les parelles possibles de manera que un punt pertanyi a la classe 1 i l'altre a la classe 0, tindrem un total de 9 parells d'aquest tipus a continuació són tots aquests 9 parells possibles.
Parella | és correcte |
|---|---|
(P1,P3) | Sí |
(P1,P4) | Sí |
(P1,P6) | Sí |
(P2,P3) | Sí |
(P2,P4) | Sí |
(P2,P6) | Sí |
(P3,P5) | No |
(P4,P5) | No |
(P5,P6) | Sí |
Aquí la columna és correcta indica si la parella esmentada està ordenada correctament en funció de la probabilitat prevista, és a dir, el punt de la classe 1 té una probabilitat més alta que el punt de la classe 0, en 7 d'aquests 9 parells possibles, la classe 1 es classifica més alta que la classe 0, o podem dir que hi ha un 77% de possibilitats que si tries un parell de punts que pertanyen a classes separades el model els pugui distingir correctament. Ara, crec que és possible que tingueu una mica d'intuïció darrere d'aquest número AUC, només per aclarir qualsevol dubte, validem-lo mitjançant la implementació de Scikit aprèn AUC-ROC.
Python 3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
Sortida:
AUC for our sample data is 0.778>
Quan hem d'utilitzar la mètrica d'avaluació AUC-ROC?
Hi ha algunes àrees on l'ús de ROC-AUC podria no ser ideal. En els casos en què el conjunt de dades està molt desequilibrat, la corba ROC pot donar una avaluació massa optimista del rendiment del model . Aquest biaix d'optimisme sorgeix perquè la taxa de falsos positius (FPR) de la corba ROC pot arribar a ser molt petita quan el nombre de negatius reals és gran.
Mirant la fórmula FPR,

observem ,
- La classe negativa és majoritària, el denominador de FPR està dominat pels veritables negatius, per la qual cosa la FPR es torna menys sensible als canvis en les prediccions relacionades amb la classe minoritària (classe positiva).
- Les corbes ROC poden ser adequades quan el cost dels falsos positius i els falsos negatius està equilibrat i el conjunt de dades no està molt desequilibrat.
En aquest cas, Corbes de precisió-record es poden utilitzar que proporcionen una mètrica d'avaluació alternativa que sigui més adequada per a conjunts de dades desequilibrats, centrant-se en el rendiment del classificador respecte a la classe positiva (minoria).
Especulant el rendiment del model
- Un AUC elevat (prop d'1) indica un excel·lent poder discriminatiu. Això significa que el model és eficaç per distingir entre les dues classes i les seves prediccions són fiables.
- Un AUC baix (prop de 0) suggereix un rendiment deficient. En aquest cas, el model lluita per diferenciar les classes positives i negatives, i les seves prediccions poden no ser fiables.
- L'AUC al voltant de 0,5 implica que el model bàsicament està fent conjectures aleatòries. No mostra cap capacitat per separar les classes, cosa que indica que el model no està aprenent cap patró significatiu de les dades.
Comprensió de la corba AUC-ROC
En una corba ROC, l'eix x representa normalment la taxa de fals positius (FPR) i l'eix y representa la taxa de positiu veritable (TPR), també coneguda com a sensibilitat o record. Per tant, un valor de l'eix x més alt (cap a la dreta) a la corba ROC indica una taxa de fals positius més alta, i un valor de l'eix y més alt (cap a la part superior) indica una taxa de positiu veritable més alt. La corba ROC és un gràfic. representació de la compensació entre la taxa vertadera positiva i la taxa de fals positiu en diversos llindars. Mostra el rendiment d'un model de classificació a diferents llindars de classificació. L'AUC (Àrea sota la corba) és una mesura resumida del rendiment de la corba ROC. L'elecció del llindar depèn dels requisits específics del problema que intenteu resoldre i de la compensació entre falsos positius i falsos negatius. acceptable en el seu context.
- Si voleu prioritzar la reducció de falsos positius (minimitzant les possibilitats d'etiquetar alguna cosa com a positiu quan no ho és), podeu triar un llindar que resulti en una taxa de falsos positius més baixa.
- Si voleu prioritzar l'augment dels positius veritables (captant tants positius reals com sigui possible), podeu triar un llindar que doni com a resultat un percentatge de positius veritables més alt.
Considerem un exemple per il·lustrar com es generen les corbes ROC per a diferents llindars i com un determinat llindar correspon a una matriu de confusió. Suposem que tenim un problema de classificació binària amb un model que prediu si un correu electrònic és correu brossa (positiu) o no correu brossa (negatiu).
Considerem les dades hipotètiques,
True Labels: [1, 0, 1, 0, 1, 1, 0, 0, 1, 0]
Probabilitats previstes: [0,8, 0,3, 0,6, 0,2, 0,7, 0,9, 0,4, 0,1, 0,75, 0,55]
Cas 1: Llindar = 0,5
True Labels | Probabilitats previstes | Etiquetes previstes |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 1 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 1 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 1 |
| 0 | 0.55 | 1 |
Matriu de confusió basada en les prediccions anteriors
| Predicció = 0 | Predicció = 1 |
|---|---|---|
Real = 0 | TP=4 | FN=1 |
Real = 1 | FP=0 | TN=5 |
D'acord amb,
- Taxa veritable positiva (TPR) :
La proporció de positius reals identificades correctament pel classificador és

- Taxa de fals positius (FPR) :
Proporció de negatius reals classificats incorrectament com a positius



Així, al llindar de 0,5:
- Veritable taxa positiva (sensibilitat): 0,8
- Taxa de fals positius: 0
La interpretació és que el model, en aquest llindar, identifica correctament el 80% dels positius reals (TPR) però classifica incorrectament el 0% dels negatius reals com a positius (FPR).
En conseqüència, per a diferents llindars obtindrem,
Cas 2: Llindar = 0,7
True Labels | Probabilitats previstes | Etiquetes previstes |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 0 |
| 0 | 0.2 data de javascript | 0 |
| 1 | 0.7 | 0 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 1 |
| 0 | 0.55 | 0 |
Matriu de confusió basada en les prediccions anteriors
| Predicció = 0 | Predicció = 1 |
|---|---|---|
Real = 0 | TP=5 | FN=0 |
Real = 1 | FP=2 | TN=3 |
D'acord amb,
- Taxa veritable positiva (TPR) :
La proporció de positius reals identificades correctament pel classificador és

- Taxa de fals positius (FPR) :
Proporció de negatius reals classificats incorrectament com a positius



Cas 3: Llindar = 0,4
True Labels | Probabilitats previstes | Etiquetes previstes |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 1 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 1 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 1 |
| 0 | 0.55 | 1 |
Matriu de confusió basada en les prediccions anteriors
| Predicció = 0 contactes bloquejats | Predicció = 1 |
|---|---|---|
Real = 0 | TP=4 | FN=1 |
Real = 1 | FP=0 | TN=5 |
D'acord amb,
- Taxa veritable positiva (TPR) :
La proporció de positius reals identificades correctament pel classificador és
- Taxa de fals positius (FPR) :
Proporció de negatius reals classificats incorrectament com a positius
Cas 4: Llindar = 0,2
True Labels | Probabilitats previstes | Etiquetes previstes |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 1 |
| 1 | 0.6 | 1 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 1 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 1 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 1 |
| 0 | 0.55 | 1 |
Matriu de confusió basada en les prediccions anteriors
| Predicció = 0 | Predicció = 1 |
|---|---|---|
Real = 0 | TP=2 | FN=3 |
Real = 1 | FP=0 | TN=5 |
D'acord amb,
- Taxa veritable positiva (TPR) :
La proporció de positius reals identificades correctament pel classificador és

- Taxa de fals positius (FPR) :
Proporció de negatius reals classificats incorrectament com a positius

Cas 5: Llindar = 0,85
True Labels | Probabilitats previstes | Etiquetes previstes |
|---|---|---|
| 1 | 0.8 | 0 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 0 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 0 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0.75 | 0 |
| 0 | 0.55 | 0 |
Matriu de confusió basada en les prediccions anteriors
| Predicció = 0 | Predicció = 1 |
|---|---|---|
Real = 0 | TP=5 | FN=0 |
Real = 1 | FP=4 | TN=1 |
D'acord amb,
- Taxa veritable positiva (TPR) :
La proporció de positius reals identificades correctament pel classificador és
- Taxa de fals positius (FPR) :
Proporció de negatius reals classificats incorrectament com a positius


A partir del resultat anterior, traçarem la corba ROC
Python 3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
Sortida:
Del gràfic s'implica que:
- La línia discontínua grisa representa el pitjor escenari, on les prediccions del model, és a dir, TPR són FPR, són les mateixes. Aquesta línia diagonal es considera el pitjor dels casos, que indica la mateixa probabilitat de falsos positius i falsos negatius.
- A mesura que els punts es desvien de la línia de conjectura aleatòria cap a la cantonada superior esquerra, el rendiment del model millora.
- L'àrea sota la corba (AUC) és una mesura quantitativa de la capacitat discriminatòria del model. Un valor AUC més alt, més proper a 1,0, indica un rendiment superior. El millor valor AUC possible és 1,0, corresponent a un model que aconsegueix el 100% de sensibilitat i el 100% d'especificitat.
En total, la corba de la característica operativa del receptor (ROC) serveix com a representació gràfica de la compensació entre la taxa de veritable positiu (sensibilitat) i la taxa de fals positiu d'un model de classificació binari a diversos llindars de decisió. A mesura que la corba ascendeix amb gràcia cap a la cantonada superior esquerra, significa la lloable capacitat del model per discriminar entre instàncies positives i negatives en una sèrie de llindars de confiança. Aquesta trajectòria ascendent indica un rendiment millorat, amb una major sensibilitat aconseguida alhora que es minimitzen els falsos positius. Els llindars anotats, indicats com A, B, C, D i E, ofereixen informació valuosa sobre el comportament dinàmic del model a diferents nivells de confiança.
Implementació mitjançant dos models diferents
Instal·lació de Biblioteques
Python 3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
Per tal d'entrenar el Bosc aleatori i Regressió logística models i per presentar les seves corbes ROC amb puntuacions AUC, l'algoritme crea dades de classificació binària artificial.
Generar dades i dividir dades
Python 3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
Utilitzant una proporció de 80-20, l'algoritme crea dades de classificació binària artificial amb 20 característiques, les divideix en conjunts d'entrenament i proves i assigna una llavor aleatòria per garantir la reproductibilitat.
Formació dels diferents models
Python 3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
Utilitzant una llavor aleatòria fixa per garantir la repetibilitat, el mètode inicialitza i entrena un model de regressió logística al conjunt d'entrenament. De manera similar, utilitza les dades d'entrenament i la mateixa llavor aleatòria per inicialitzar i entrenar un model de bosc aleatori amb 100 arbres.
Prediccions
Python 3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
Utilitzant les dades de la prova i un entrenat Regressió logística model, el codi prediu la probabilitat de la classe positiva. De manera similar, utilitzant les dades de la prova, utilitza el model de bosc aleatori entrenat per produir probabilitats projectades per a la classe positiva.
Creació d'un marc de dades
Python 3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
Utilitzant les dades de prova, el codi crea un DataFrame anomenat test_df amb columnes etiquetades True, Logistic i RandomForest, afegint etiquetes reals i probabilitats previstes dels models Random Forest i Logistic Regression.
Traceu la corba ROC per als models
Python 3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
Sortida:

El codi genera una trama amb figures de 8 per 6 polzades. Calcula la corba AUC i ROC per a cada model (Random Forest and Logistic Regression) i després dibuixa la corba ROC. El corba ROC per a endevinar aleatòriament també es representa amb una línia discontínua vermella, i s'estableixen etiquetes, un títol i una llegenda per a la visualització.
Com utilitzar ROC-AUC per a un model multiclasse?
Per a una configuració multiclasse, simplement podem utilitzar una metodologia contra totes i tindreu una corba ROC per a cada classe. Suposem que teniu quatre classes A, B, C i D, llavors hi hauria corbes ROC i valors AUC corresponents per a les quatre classes, és a dir, un cop A seria una classe i B, C i D combinades serien les altres classes. , de la mateixa manera, B és una classe i A, C i D es combinen com a altres classes, etc.
Els passos generals per utilitzar AUC-ROC en el context d'un model de classificació multiclasse són:
Metodologia d'un contra tots:
- Per a cada classe del vostre problema multiclasse, tracteu-la com a classe positiva mentre combineu totes les altres classes a la classe negativa.
- Entrena el classificador binari de cada classe contra la resta de classes.
Calcula l'AUC-ROC per a cada classe:
- Aquí tracem la corba ROC per a la classe donada contra la resta.
- Traceu les corbes ROC per a cada classe en el mateix gràfic. Cada corba representa el rendiment de discriminació del model per a una classe específica.
- Examineu les puntuacions AUC de cada classe. Una puntuació AUC més alta indica una millor discriminació per a aquesta classe en particular.
Implementació d'AUC-ROC en Classificació Multiclasse
Importació de biblioteques
Python 3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
El programa crea dades multiclasse artificials, les divideix en conjunts d'entrenament i proves i després utilitza el Un vs. Restclassificador tècnica per entrenar classificadors tant per a la regressió forestal aleatòria com per a la regressió logística. Finalment, dibuixa les corbes ROC multiclasse dels dos models per demostrar com discriminen entre diverses classes.
Generació de dades i divisió
Python 3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
Tres classes i vint característiques conformen les dades multiclasse sintètiques produïdes pel codi. Després de la binarització de l'etiqueta, les dades es divideixen en conjunts d'entrenament i proves en una proporció de 80-20.
Models de formació
Python 3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
El programa entrena dos models multiclasse: un model de bosc aleatori amb 100 estimadors i un model de regressió logística amb el Enfocament d'un contra descans . Amb el conjunt de dades d'entrenament, s'ajusten ambdós models.
Traçant la corba AUC-ROC
Python 3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
Sortida:

Les corbes ROC i les puntuacions AUC dels models de regressió logística i forestal aleatòria es calculen pel codi de cada classe. A continuació, es dibuixen les corbes ROC multiclasse, mostrant el rendiment de discriminació de cada classe i amb una línia que representa una endevinació aleatòria. La trama resultant ofereix una avaluació gràfica del rendiment de classificació dels models.
Conclusió
En l'aprenentatge automàtic, el rendiment dels models de classificació binària s'avalua mitjançant una mètrica crucial anomenada Area Under the Receiver Operating Characteristic (AUC-ROC). A través de diversos llindars de decisió, mostra com es compensa la sensibilitat i l'especificitat. Normalment, un model amb una puntuació AUC més alta mostra una major discriminació entre instàncies positives i negatives. Mentre que 0,5 denota atzar, 1 representa un rendiment impecable. L'optimització i la selecció de models s'ajuden amb la informació útil que ofereix la corba AUC-ROC sobre la capacitat d'un model per discriminar entre classes. Quan es treballa amb conjunts de dades o aplicacions desequilibrades on els falsos positius i els falsos negatius tenen costos diferents, és especialment útil com a mesura integral.
Preguntes freqüents sobre la corba AUC ROC en aprenentatge automàtic
1. Què és la corba AUC-ROC?
Per a diversos llindars de classificació, la compensació entre la taxa de veritable positiu (sensibilitat) i la taxa de fals positiu (especificitat) es representa gràficament per la corba AUC-ROC.
2. Com és una corba AUC-ROC perfecta?
Una àrea d'1 en una corba ideal AUC-ROC significaria que el model aconsegueix una sensibilitat i especificitat òptimes en tots els llindars.
3. Què significa un valor AUC de 0,5?
AUC de 0,5 indica que el rendiment del model és comparable al de l'atzar aleatori. Suggereix una manca de capacitat de discriminació.
4. Es pot utilitzar AUC-ROC per a la classificació multiclasse?
AUC-ROC s'aplica amb freqüència a problemes relacionats amb la classificació binària. Per a la classificació multiclasse es poden tenir en compte variacions com l'AUC de la macro-mitjana o la micro-mitjana.
5. Com és útil la corba AUC-ROC en l'avaluació del model?
La capacitat d'un model per discriminar entre classes es resumeix de manera exhaustiva per la corba AUC-ROC. Quan es treballa amb conjunts de dades desequilibrats, és especialment útil.